
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- fosslight
- supabase
- elastic search
- 자료구조
- devops
- prometeus
- 하이브리드 데이터 모델
- umc
- C++
- docker
- API Gateway
- curl
- java
- ELK
- konga
- 화자분리
- jwt-java
- kong
- 파이썬
- OpenSource
- Nice
- mybatis
- 메소드
- DI
- Spring
- template/callback
- roll over
- pyannote
- metricbeat
- monitoring
- Today
- Total
youngseo's TECH blog
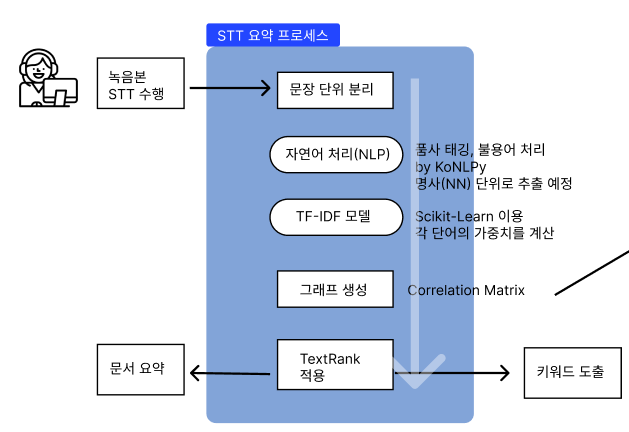
[ALGORITHM|TEXTRANK] 텍스트 속 주요 문장들 도출시키기 본문
개요
Whisper STT 과제에 이어, 추출된 문장들을 요약하는 과제가 추가되었다.
문장 요약 방법 2가지
문장 요약에는 크게 추출적 요약(Extractive Summarization)과 추상적 요약(Abstractive Summarization)으로 나누어진다. 추상적 요약은 AI를 이용해 나름대로 새로운 문장으로 요약을 하는 것이고, 추출적 요약은 말 그대로 글에서 중요한 문장만을 추출시켜 요약하는 것이다. 우선 추출적 요약을 사용해보기로 하였다.
페이지링크 알고리즘
우리가 쓰려는 텍스트랭크 알고리즘은 페이지랭크 알고리즘을 기반으로 한다.
페이지링크는 더 중요한 페이지는 더 많은 다른 사이트로부터 링크를 받는다는 관찰에 기초한 검색기술이다.
웹페이지는 정점, 그리고 웹페이지가 포함하는 하이퍼링크는 해당 웹페이지에서 나가는 간선으로 표현해보자.
하이퍼링크란 잘 알다시피, 하이퍼텍스트 문서 안에서 직접 모든 형식의 자료를 연결하고 가리킬 수 있는 참조 고리를 의미한다.
이 알고리즘의 핵심 아이디어
이 알고리즘의 핵심 아이디어는 ‘투표’이다. 즉, 투표를 통해 사용자 키워드와 관련성이 높고 신뢰할 수 있는 웹페이지를 찾는다.
이 때 투표의 주체는 바로 웹페이지이고, 웹 페이지는 하이퍼링크를 통해 투표한다.
마치, 논문을 고를 때 우리도 많이 인용된 논문을 더 많이 신뢰하는 것처럼, 더 많은 하이퍼링크를 가진 웹페이지의 투표수가 올라간다고 생각하면 된다.
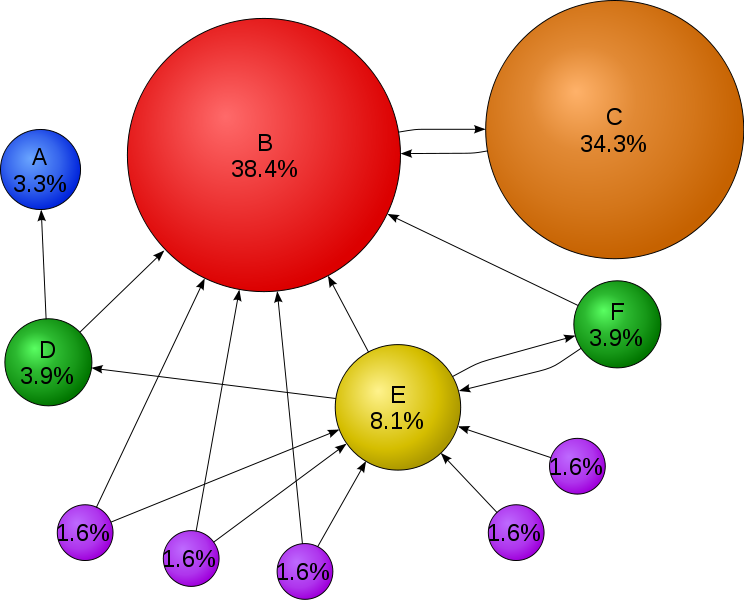
페이지링크 알고리즘을 응용해 만든, 텍스트랭크 알고리즘
키워드 와 핵심 문장 추출
결론적으로 내가 사용하고자 하는 알고리즘이다 !
위의 페이지링크 알고리즘 개념을 응용하여 만든 것으로, word graph나 sentence graph를 구축한 후 Graph ranking 알고리즘이 만들어졌다. 이를 이용해 키워드나 핵심 문장을 뽑아낼 수 있다.
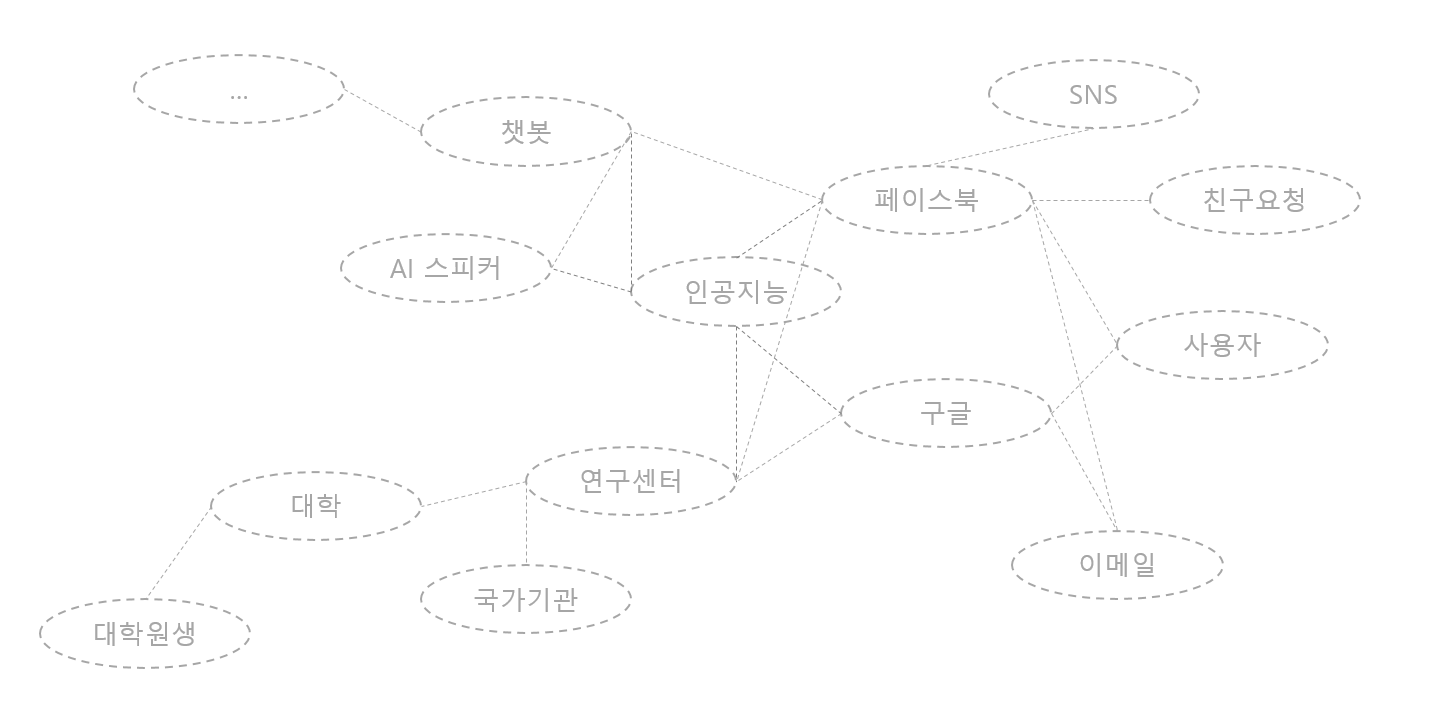
무슨 기준으로 그래프로 둘의 연관성을 나타내지?
위의 그래프를 보면 챗봇과 인공지능의 연관성은 짙게 표시되고, 대학과 구글의 연관성은 옅게 표시되어 있는 것을 알 수 있다. 이렇게 문장 내에서의 co-occurence와 토픽 정보를 바탕으로 유사도를 정의하여 단어 그래프를 만든다. 이후 중요한 단어(키워드) 는 아래와 같은 수식에 의해 매긴다고 한다.
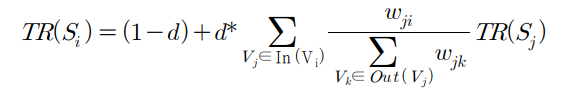
Wji는 정점 Si와 Sj 사이의 간선 가중치를 나타내고, In(Vi)는 단어 Vi와 연결되어 있는 모든 단어들의 집합, Out(Vj)는 단어 Vj와 연결되어 있는 모든 단어들의 집합이다. d는 제동계수로, PageRank에서 웹 서핑을 하는 사람이 현재 페이지에 만족하지 못하고 다른 페이지로 가는 링크를 클릭할 확률로 0.85를 사용한다.
그럼 이 유사도는 어떻게 나타내지?
간단하게 설명하자면, Co-occurence는 문장 내에서 두 단어의 간격이 window인 횟수를 의미한다. 동시 발생 이라는 뜻의 co-occurence는 텍스트 내에서 두 단어가 얼마나 서로 가깝게 등장하는가로 측정된다. 만약 window 값이 7이라면 한 문장에서 이 둘 사이의 간격이 7 이내인 경우를 count하는 것이다.
co-occurence는 대규모 텍스트 데이터에서 많은 문장들을 분석한 값이다. 즉, 우리는 여러 텍스트 데이터들을 넣어서 문장들을 분석한 후에 두 단어의 유사도를 도출할 수 있다.
이렇듯 TextRank 알고리즘은 비지도 학습 기반이기 때문에 'AI 지도 학습'을 시키지 않아도 된다는 점에서 강력하다.
TF-IDF란?
우선 DTM 개념에 대해 이해하자.
DTM이란 문서 단어 행렬을 뜻하는 말로, 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것을 의미한다. 그러면 문서 10개에서 "고객님"이라는 단어가 각각 2번 이상 출현했다고 가정해보자. 고객님 이라는 단어는 불용어는 아니나해당 문서 요약에서 그리 중요한 단어가 아니다.
DTM 자체는 one-hot 벡터와 비슷하게 희소 벡터라 많은 저장공간을 필요로 한다는 점과, 단순 빈도수 기반으로 접근한다는 점에서 한계를 가진다.
이 한계를 극복하기 위해 DTM에 불용어/중요단어에 가중치를 부여하자는 것이 TF-IDF이다. 특정 문서에서만 자주 등장한다면, 중요도가 높다. 하지만, 여러 문서에서 자주 등장하면 중요도가 낮다.
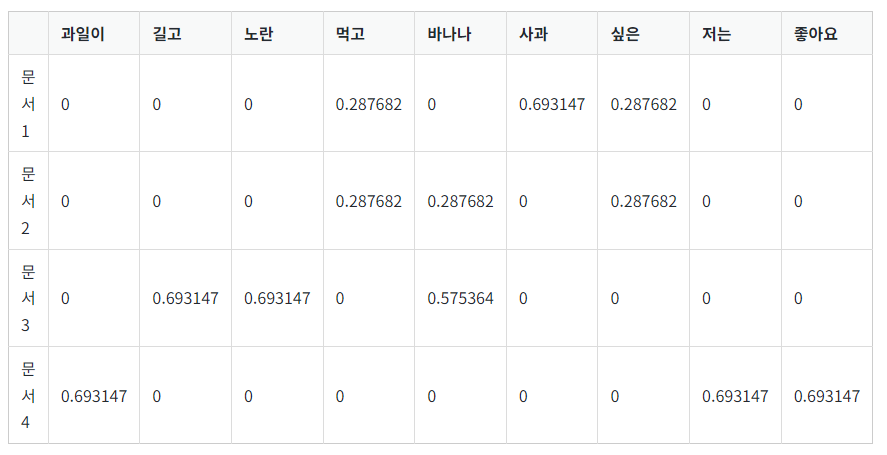
TF-IDF 또한 벡터화된 값이다. 이 벡터화된 값은 어떤 것을 기준으로 할까? 이름이 힌트다 ! 간단히 말해 아래의 두 개를 곱한 값을 기준으로 한다.
- TF : 해당 문서 내 특정 단어가 얼마나 자주 등장하는가
- IDF : 전체 문서 집합 내에서 특정 단어가 얼마나 고유한가
위의 그래프를 보다보면 하나 헷갈릴 수 있는 것이 있는데 문서1, 문서2 ..는 사실상 '문장'이다.
신문 기사를 예로 들면 하나의 신문기사 속에 문장1, 문장2, 문장3 .. 이것들이 위 그래프의 행에 속한다.
주요 키워드 및 문장 추출하기
해당 블로그를 응용하여 만들었습니다.
from konlpy.tag import Kkma
from konlpy.tag import Twitter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import normalize
import numpy as np #이 때 버전은 1.23 이하로 해야 메모리 이슈를 막을 수 있음우선 불용어에 해당하는 자료들을 경로 "./불용어.txt"에 저장해두었다. "고객님" 이런 단어들 또한 불용어로 저장할 수 있도록 따로 파일로 빼두었고
네 네. 네, 네? 네.. 모두 불용어로 처리될 수 있도록 특수문자도 포함시켜주는 부분을 추가하였다.
import re
def read_stopwords(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
stopwords = [word.strip() for word in file.readlines() if word.strip()]
# 특수문자가 추가된 경우를 함께 포함시켜주는 부분 추가
extended_stopwords = []
for word in stopwords:
extended_stopwords.extend([word, f"{word}.", f"{word},", f"{word}, ", f"{word}..", f"{word}...", f"{word}?", f"{word}!", f"{word}. "])
return extended_stopwords
stopwords_file_path = '불용어.txt'
stopwords = read_stopwords(stopwords_file_path)파이썬을 이용하여 객체 지향적인 코드로 구현되어 있다.
우선 KoNLPy의 꼬꼬마(Kkma)를 이용해 주어진 텍스트를 문장 단위로 바꾼다. 문장의 길이가 10 이하이면 이전 문장과 합친다.
또한 KoNLPy의 Twitter를 이용해 명사만을 추출한다.
class SentenceTokenizer(object):
def __init__(self):
self.kkma = Kkma() #문장으로 바꾸는 데에 사용
self.twitter = Twitter() #명사만 가져오는 데에 사용
self.stopwords = stopwords #./불용어.txt에서 가져올 예정
def text2sentences(self, text):
sentences = self.kkma.sentences(text) #꼬꼬마를 이용해 sentence로 바꾼다.
for idx in range(0, len(sentences)):
if len(sentences[idx]) <= 10:
sentences[idx-1] += (' ' + sentences[idx])
sentences[idx] = ''
return sentences
def get_nouns(self, sentences): #명사만 가져온다.
nouns = []
for sentence in sentences:
if sentence != '':
nouns.append(' '.join([noun for noun in self.twitter.nouns(str(sentence))
if noun not in self.stopwords and len(noun) > 1]))
return nouns이후 numpy를 사용하여 TF(단어의 빈도)와 IDF(역 문서 빈도) 벡터를 곱한다.
TF(d,t) = 특정 문서 d에서의 특정 단어 t의 등장 횟수이고, IDF(d, t) = df(t)에 반비례하는 수이다.
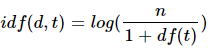
sentence 그래프와 words 그래프를 각각 도출한다.
class GraphMatrix(object):
def __init__(self):
self.tfidf = TfidfVectorizer()
self.cnt_vec = CountVectorizer()
self.graph_sentence = []
def build_sent_graph(self, sentence):
tfidf_mat = self.tfidf.fit_transform(sentence).toarray()
self.graph_sentence = np.dot(tfidf_mat, tfidf_mat.T)
return self.graph_sentence
def build_words_graph(self, sentence):
cnt_vec_mat = normalize(self.cnt_vec.fit_transform(sentence).toarray().astype(float), axis=0)
vocab = self.cnt_vec.vocabulary_
return np.dot(cnt_vec_mat.T, cnt_vec_mat), {vocab[word] : word for word in vocab}이제 위의 TF-IDF를 이용해 TextRank 알고리즘을 적용한다.
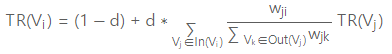
class Rank(object):
def get_ranks(self, graph, d=0.85): # d = damping factor 해당 사용자가 현재 페이지에 만족하고 계속 보는 확률
A = graph
matrix_size = A.shape[0]
for id in range(matrix_size):
A[id, id] = 0 # diagonal 부분을 0으로
link_sum = np.sum(A[:,id]) # A[:, id] = A[:][id]
if link_sum != 0:
A[:, id] /= link_sum
A[:, id] *= -d
A[id, id] = 1
B = (1-d) * np.ones((matrix_size, 1))
ranks = np.linalg.solve(A, B) # 연립방정식 Ax = b
return {idx: r[0] for idx, r in enumerate(ranks)}위의 객체들을 이용해 최종 TextRank Class를 구현한다. 이 클래스로 요약 및 키워드를 도출할 수 있다.
class TextRank(object):
def __init__(self, text):
self.sent_tokenize = SentenceTokenizer()
self.sentences = self.sent_tokenize.text2sentences(text)
self.nouns = self.sent_tokenize.get_nouns(self.sentences)
self.graph_matrix = GraphMatrix()
self.sent_graph = self.graph_matrix.build_sent_graph(self.nouns)
self.words_graph, self.idx2word = self.graph_matrix.build_words_graph(self.nouns)
self.rank = Rank()
self.sent_rank_idx = self.rank.get_ranks(self.sent_graph)
self.sorted_sent_rank_idx = sorted(self.sent_rank_idx, key=lambda k: self.sent_rank_idx[k], reverse=True)
self.word_rank_idx = self.rank.get_ranks(self.words_graph)
self.sorted_word_rank_idx = sorted(self.word_rank_idx, key=lambda k: self.word_rank_idx[k], reverse=True)
def summarize(self, sent_num=4):
summary = []
index=[]
for idx in self.sorted_sent_rank_idx[:sent_num]:
index.append(idx)
index.sort()
for idx in index:
summary.append(self.sentences[idx])
return summary
def keywords(self, word_num=10):
rank = Rank()
rank_idx = rank.get_ranks(self.words_graph)
sorted_rank_idx = sorted(rank_idx, key=lambda k: rank_idx[k], reverse=True)
keywords = []
index=[]
for idx in sorted_rank_idx[:word_num]:
index.append(idx)
#index.sort()
for idx in index:
keywords.append(self.idx2word[idx])
return keywordstext = """
내소망은 단순하게 사는 일이다.
그리고 평범하게 사는 일이다.
내 느낌과 의지대로 자연스럽게 살고 싶다.
그 누구도 내 삶을 대신해서 살아줄 수없기 때문에 나는 나답게 살고 싶다.
모든 사람이 싫어하더라도 반드시 살펴보아야 하고,
뭇사람이 좋아하더라도 반드시 살펴보아야 하느니라.
"""
textrank = TextRank(text)
for row in textrank.summarize(3):
print(row)
print()
print('keywords :',textrank.keywords())
'''
내 소망은 단순하게 사는 일이다.
그리고 평범하게 사는 일이다.
내 느낌과 의지대로 자연스럽게 살고 싶다.
keywords : ['나답', '느낌', '대신', '때문', '의지', '자연', '모든', '사람', '소망', '일이']
'''자체 평가
우선 긴 문장의 경우 numpy 계산 도중 메모리 이슈로 Kernel이 죽는 현상이 발견된다. 이를 해결할 방법을 좀 더 생각해보아야 할 것 같다. TF-IDF 모델을 다른 방식으로 계산한다거나 계산량을 줄이는 방법을 생각해봐야 할 것 같다.
사내 주요 특정 키워드에 가중치를 더 크게 부여하는 것을 추가 요청받았다. 이 점을 어떻게 반영할지 생각해봐야겠다.
이후 추상적 요약도 적용할 예정이다. 위에서 도출되는 추출적 요약을 어떻게 반영시킬지 고민해보아야 겠다.
2024.01.12 글 업데이트 !
Sciklearn의 문서 전처리 라이브러리를 이용하여 메모리 오류 없이 TF-IDF 계산을 처리할 수 있다.
아래의 코드를 통해 docs1, docs2, docs3 .. 리스트 데이터를 이용해 계산해보았다. 조사, 문장부호, 접미사, 그리고 내가 지정해둔 stopwords를 제외하도록 전처리 후 TF-IDF를 실시한다.
from konlpy.tag import Okt
from sklearn.feature_extraction.text import TfidfVectorizer
class MyTokenizer:
def __init__(self, tagger):
self.tagger = tagger
def __call__(self, sent):
pos = self.tagger.pos(sent, stem = True)
pos = ['{}/{}'.format(word,tag) for word, tag in pos]
return pos
my_tokenizer = MyTokenizer(Okt())
contents_for_vectorize = ['docs1', 'docs2', 'docs3' ...]
for content in conversations:
temp = ''
print(my_tokenizer(content))
for i in my_tokenizer(content):
word, sort = i.split('/')
if sort in ['Josa', 'Punctuation', 'Suffix', 'Foreign'] or word in stopwords:continue
temp+= i.split('/')[0]+' '
contents_for_vectorize.append(temp)
print(contents_for_vectorize)
# TF-IDF 모델 생성
tfidf_vectorizer = TfidfVectorizer(stop_words=list(stopwords), max_features=10000)
tfidf_matrix = tfidf_vectorizer.fit_transform(contents_for_vectorize)
threshold_score = 0.12
filtered_all_words = []
# 단어별 TF-IDF 값을 출력
feature_names = tfidf_vectorizer.get_feature_names_out()
for doc_idx, doc in enumerate(contents_for_vectorize):
filtered_words = []
print(f"Document {doc_idx + 1}: {doc}")
# TF-IDF 행렬에서 현재 문서의 비영행렬 요소 추출
feature_index = tfidf_matrix[doc_idx, :].nonzero()[1]
# 단어와 해당 단어의 TF-IDF 값을 가져와 출력
for word_idx in feature_index:
word = feature_names[word_idx]
tfidf_score = tfidf_matrix[doc_idx, word_idx]
print(f" Word: '{word}', TF-IDF: {tfidf_score:.4f}")
if tfidf_score > threshold_score:
filtered_words.append([-tfidf_score, word])
filtered_words.sort()
print("결과",filtered_words)
filtered_all_words +=filtered_words
print(filtered_all_words)결론적으로 TF-IDF는 한 도메인으로 통용되는 자료들에 도입하기에는 적절하지 않다. “다른 문서에서는 등장하지 않지만 특정 문서에서는 자주 등장하는 단어를 찾아내 문서 내 중요한 단어의 가중치를 계산하는 방법”에 가깝기 때문이다.
우리 회사 도메인에서는 ‘입금, 연체, 미납’ 등의 정해진 단어들이 중요한데 모든 docs에서 이 단어들이 골고루 나오기 때문에 특정 문서의 중요 단어들에서 오히려 이 단어들을 제외시키는 문제가 발생했다. 따라서 우리 회사 도메인 중요 문장 도출에 TF-IDF는 적절하지 않다고 판단, 도메인 사전을 만드는 것으로 구현 방향을 변경하였다.
'알고리즘' 카테고리의 다른 글
| [PS|애드훅] 백준 1034 램프 (1) | 2023.11.23 |
|---|
