
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- prometeus
- metricbeat
- Spring
- template/callback
- roll over
- DI
- devops
- docker
- fosslight
- Nice
- mybatis
- ELK
- 메소드
- 자료구조
- kong
- konga
- API Gateway
- supabase
- 하이브리드 데이터 모델
- umc
- pyannote
- curl
- jwt-java
- C++
- OpenSource
- elastic search
- monitoring
- 파이썬
- java
- 화자분리
- Today
- Total
youngseo's TECH blog
[크롤링|Lambda] AWS Lambda를 이용해 백준, 티스토리 크롤링하기 본문
개요
2년간 열심히 활동했던 Koala 동아리를 이제 내려놓게 되었다 ! 지금껏 Koala 출석부 작성은 노가다성이었기 때문에 다음 기수 친구들의 고통을 덜어주고자 급하게 12월부터 코알라 출석부를 제작하기 시작했다. front부터 back까지 전 과정을 내가 스스로 구현하는(하지만 front는 매우 허접한) 프로젝트를 완성시켜보고 싶은 바램도 있었기에 의미있는 작업이었다.
Serverless
서버리스란 ‘서버가 없다’는 것이 아니고, ‘필요할때만 서버가 존재한다’는 것을 의미한다. EC2에 Docker image를 가동시켜 서버를 띄울 때에는 24시간 내내 서버가 떠있다. 하지만 스케줄링에 의해 작업되는 크롤링이라던가 특정 시간에만 서버를 사용하는 서비스라면, 굳이 24시간 내내 서버를 띄울 필요가 없다.
따라서 비용이나 서버 관리 측면에서 장점을 가지지만, 콜드 스타트 지연 등 수행시간이나 병렬처리 등의 복잡한 인프라 구성의 한계 등의 단점 또한 가진다.
AWS Lambda
따라서 서버 내 스케줄링 작업(Springboot의 @Scheduling 어노테이션 사용)보다는 Lambda Function을 통해 서버 관여 없이 RDS에서 직접 데이터를 가져오고 전송하는 아키텍처를 선택하였다.

크롤링 요구사항
1. 백준 아이디로 푼 문제 크롤링한다.
맞은 문제 리스트를 매주 일요일마다 크롤링하여 일주일마다 푼 문제를 DB에 저장한다. 그렇다면 이번주에 푼 문제 개수는 [이번주까지 푼 문제-저번주까지 푼 문제]로 적용할 수 있다.
2. 백준 연습 문제 푼 사람 크롤링
우리 동아리에서는 자체적으로 그룹 내 연습을 만들어 정해진 스터디별 문제를 출제하여 풀 수 있도록 하고 있다. 이 페이지도 크롤링하고 싶었으나, 이 페이지에 들어가려면 기본적으로 login이 가능해야 하는데 백준에서 /login url은 크롤링 등의 로봇 접근을 제한한 것을 알 수 있었다.
robots.txt로 크롤링이 제한된 url을 확인할 수 있다.
3. 티스토리 크롤링
티스토리 글들은 카카오 로그인 후 카테고리 & 날짜 및 시간 적용하여 검색 후 크롤링하여 각 사람별로 주 별 작성글 수를 넣어준다.
크롤링 구현
우선 아래에서 쓰이는 라이브러리를(import) 사용할 수 있도록 Lambda 함수 계층에 chromedriver, bs4, selenium, pymysql 라이브러리를 압축하여 하나씩 넣어주었다.
크롤링 함수는 다음과 같이 구현할 수 있다.
lambda_funciton.py
import json
from tistory import tistory_crawling
from backjoon import backjoon_crawling
def lambda_handler(event, context):
a = backjoon_crawling()
b = tistory_crawling()
response = {
"backjoon_crawling": a,
"tistory_crawling": b
}
print(response)
return {
"statusCode": 200,
"body": json.dumps(response)
}backjoon.py
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
import json
import time
def backjoon_crawling():
student_list=["20wjsdudtj"]
for student in student_list:
url = 'https://www.acmicpc.net/user/'+student
problem_num = []
req = Request(url=url, headers={'User-Agent': 'Mozilla/5.0'})
response = urlopen(req).read()
time.sleep(10)
# 성공적으로 data(html)를 받아왔다면
print("Success!!")
# BeautifulSoup을 사용하여 data를 파싱
soup = BeautifulSoup(response, 'html.parser')
for item in soup.select('div.panel-default:nth-of-type(2) > div.panel-body > div.problem-list > a'):
problem_num.append(item.text)
print(student,problem_num)
return {
'statusCode': 200,
'body': json.dumps('백준 크롤링 성공')
}tistory.py
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.options import Options
import boto3,json
from urllib.parse import quote
from selenium.webdriver.common.keys import Keys
def tistory_crawling():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--window-size=1280x1696')
chrome_options.add_argument('--user-data-dir=/tmp/user-data')
chrome_options.add_argument('--hide-scrollbars')
chrome_options.add_argument('--enable-logging')
chrome_options.add_argument('--log-level=0')
chrome_options.add_argument('--v=99')
chrome_options.add_argument('--single-process')
chrome_options.add_argument('--data-path=/tmp/data-path')
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument('--homedir=/tmp')
chrome_options.add_argument('--disk-cache-dir=/tmp/cache-dir')
chrome_options.add_argument('user-agent=Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36')
chrome_options.binary_location = "/opt/python/bin/headless-chromium"
driver = webdriver.Chrome('/opt/python/bin/chromedriver', chrome_options=chrome_options)
# 웹 페이지 열기
driver.get("https://www.tistory.com/auth/login")
# 원하는 웹 페이지 URL로 변경
time.sleep(40)
driver.find_element(By.CLASS_NAME, "btn_login").click()
time.sleep(40)
# 아이디와 비밀번호 입력
id_input = driver.find_element(By.ID, "loginId--1")
id_input.send_keys("카카오 아이디") # 카카오 아이디
password_input = driver.find_element(By.ID, "password--2")
password_input.send_keys("카카오 비번") # 카카오 비밀번호 입력
driver.find_element_by_class_name("btn_g").click()
time.sleep(40)
driver.get("https://kau-algorithm.tistory.com/manage/posts?category=1056752")
time.sleep(30)
page_source = driver.page_source
# BeautifulSoup으로 파싱
soup = BeautifulSoup(page_source, 'html.parser')
print(soup)
# 원하는 데이터 추출
ul_element = soup.find('ul', class_='list_post_type2')
time.sleep(10)
if ul_element:
li_elements = ul_element.find_all('li')
data_list = []
time.sleep(5)
for li in li_elements:
li_data = {}
link_cont = li.find("a", class_="link_cont")
if link_cont:
li_data["link_cont"] = link_cont.get_text()
txt_info_txt_ellip = li.find("span", class_="txt_info txt_ellip")
if txt_info_txt_ellip:
li_data["txt_info_txt_ellip"] = txt_info_txt_ellip.get_text()
txt_info = li.find("span", class_="txt_info")
if txt_info:
li_data["txt_info"] = txt_info.get_text()
data_list.append(li_data)
for data in data_list:
print(data)
driver.quit()
return data_list
else:
print("No 'ul' element found on the page.")
driver.quit()
return None배열로 내가 원하는 값들을 꺼내올 수 있다.
트러블 슈팅
⚠카카오 로그인
Tistory kakao 로그인 시 여기 에서 참고하여 2단계 인증을 풀어주었다.
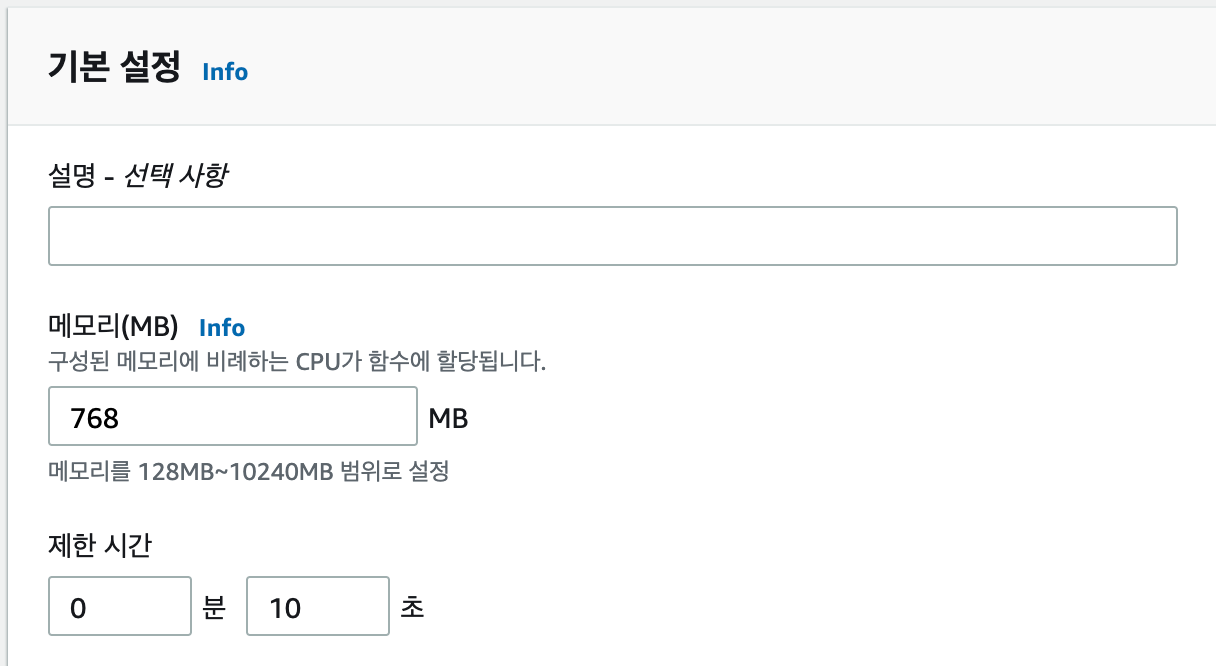
⚠테스트는 성공했는데 body에 값이 없다면 메모리 및 제한 시간을 늘려주자.
⚠중간중간 time.sleep(20) 설정 넉넉히 !
Local에서 크롤링할 때에 비해 chromedriver가 화면을 천천히 렌더링할 가능성이 높다. time.sleep() 설정을 넉넉히 주어야 한다.
'BackEnd' 카테고리의 다른 글
| [DB] RDS DB 마이그레이션 과정 - RDB와 NoSQL (0) | 2024.01.06 |
|---|---|
| [ELK|Python] REST API로 ES에 데이터 색인하기 (0) | 2024.01.04 |
| [API] URL/URI 와 RESTFul API 설계 방법 (3) | 2023.12.20 |
| [Java] 클린코드2 (2) | 2023.10.08 |
| [Java] 클린코드1 (7) | 2023.10.04 |


