

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Nice
- OpenSource
- 자료구조
- 메소드
- kong
- jwt-java
- metricbeat
- roll over
- java
- 파이썬
- mybatis
- DI
- konga
- prometeus
- API Gateway
- 하이브리드 데이터 모델
- supabase
- curl
- 화자분리
- devops
- ELK
- pyannote
- monitoring
- template/callback
- C++
- fosslight
- Spring
- elastic search
- docker
- umc
- Today
- Total
youngseo's TECH blog
[ELK] 텍스트를 이용해 키워드 추출 본문
앞서 Elastic에 text 파일들을 index로 적재해보았다. 이번에는 해당 텍스트들을 이용해 키워드를 추출하고, 키워드들이 총 몇개의 docs에 나타나는지를 추려볼 예정이다(terms 집계). 최종 목표는 '회사 도메인 사전' 만들기이다. 다시 말해 상담 TEXT 기록 내에서 사용되는 용어들을 수집하여, 이를 하나의 사전처럼 나타낼 계획이다.
인덱스의 정보 단위
인덱스의 정보단위로 /_settings와 /_mappings 가 사용된다.
주로 PUT <인덱스명>으로 인덱스를 처음 생성한 후에
GET <인덱스명>/_settings 또는 GET <인덱스명>/_mappings( _settings )로 index에 대한 정보들을 따로 볼 수 있다.
- _settings: 샤드 수나 복제본 수 등 설정 가능
- _mappings: 미리 정의하지 않아도 인덱스에 도큐먼트를 새로 추가하면 자동으로 매핑이 설정되어 저장되는 이유이다. 필드 타입(text, date ..) 등을 파악 가능
index 구성
index 구성은 아래와 같다. elastic_test 라는 index 아래 여러 docs들이 매핑되는 형태이다.
글은 나의 쌉오글거리는 2023 후기글을 가져왔다.
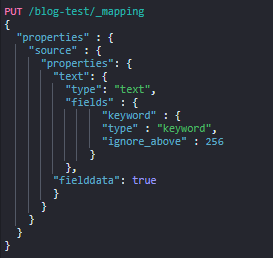
인덱스 매핑을 이용해 fielddata=true 필드 추가
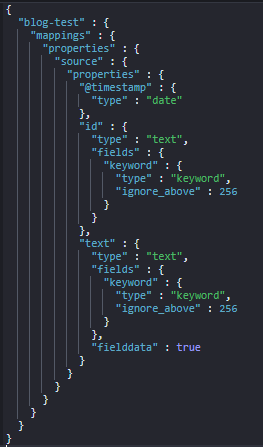
엘라스틱서치는 동적 매핑을 지원하기 때문에 도큐먼트 추가 시 자동으로 매핑이 가능하다는 특징이 있다. 내 docs는 JSON 형태로 id, text, @timestamp 의 세 가지 값들을 추가하고 있다. 각각의 type은 text, text , date 이다. 앞에서 내가 정의한 text는 변수명이다.. 헷갈려서 바꿔야할 필요가 있겠다,,
이 때 text 필드는 기본적으로 검색은 가능하나 집계, 정렬 또는 스크립팅에는 사용할 수 없다.
기본적으로 ES의 검색은 '어떤 문서가 이 키워드를 포함하는지가 궁금'하므로 역인덱스된 정보를 통해 빠른 검색이 가능하게 해준다고 했다.. 즉, docs가 추가될 때 term으로 나누어서 역인덱스 구조를 가지게 된다. 나는 여기에서 당연히 이 역인덱스 테이블을 통해 집계, 정렬을 쉽게 할 수 있을 줄 알았다..
그러나 sort, aggregation, accessing field value와 같은 패턴은 '이 문서에서 이 field value값이 무엇인지'가 관심이므로 역인덱스 정보가 아닌 document를 key로, field 정보를 담은 데이터 구조가 필요하다. 즉, 역인덱스가 아닌 일반 인덱스 구조여야 가능하다는 것이다.

따라서 fielddata=true 를 적용해야 한다.
Bucket Aggregations
이제 만든 fielddata에 대한 terms를 바탕으로 문자열 통계를 내보자 !
Bucket Aggregations는 SQL GROUP BY COUNT 및 AVERAGE 함수와 유사하다는 설명으로 이해하면 좋다.
그 중 terms 집계는 버킷이 동적으로 생성되는 다중 버킷 집계이다. 집계 시 지정한 필드에 대해 빈도수가 높은 텀의 순위로 결과가 반환된다.
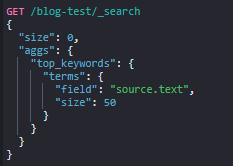
아래와 같이 key로는 term을 반환하고 doc_count 로는 해당 단어를 가진 docs의 갯수를 반환한다.
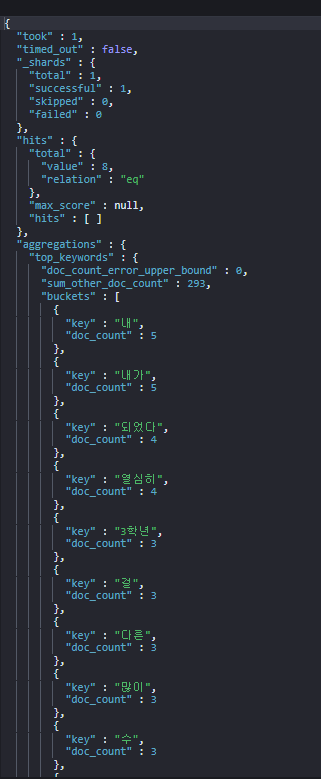
Kibana 시각화
Kibana 시각화를 통해 위의 자료들을 표현하면 아래와 같이 나오게 된다 !

정리
위의 시각화 데이터를 보면 '내', '내가' 는 사실상 조사만 추가되었을 뿐 같은 단어로 처리하는 것이 필요하다. nori 한글 분석기를 적용하여 처리하려 했으나 집계함수를 실행하는 동안에는 이 분석기를 사용할 수 없다. 다른 과정을 통해 analyzer를 적용해보자.
field data :true 설정은 field data를 사용하는 text 는 분석된 채로 heap 메모리에 로딩되기 때문에 상당한 메모리를 사용한다고 한다. 이를 예방하기 위해 상위 회로 차단기 등을 도입하여 OOM 오류를 막을 수 있다. 집계함수 구현 방법 외에 검색 엔진 형태라던가 다른 데이터 쿼리 방법을 사용해 보는 것이 좋겠다.
'BackEnd > DEVOPS' 카테고리의 다른 글
| [CICD|AWS] 무중단배포, 다운타임을 없애자! Elastic Beanstalk (0) | 2024.06.20 |
|---|---|
| [CD|Cloud RUN] Google Cloud Run으로 지속적 배포 구현하기 (2) | 2024.01.03 |
| [Serverless|Cloud RUN] Google Cloud Run으로 JAVA WAR 파일 배포하기 (2) | 2024.01.02 |
| [DEVOPS] Linux 환경에서 ELK metricbeat를 사용한 시스템 모니터링 (0) | 2023.09.02 |
| [Kafka] Kafka 이론 및 실습(Window10 Local 환경) (0) | 2023.08.11 |



