
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- jwt-java
- konga
- ELK
- 화자분리
- docker
- OpenSource
- C++
- roll over
- java
- 파이썬
- pyannote
- elastic search
- curl
- API Gateway
- mybatis
- 하이브리드 데이터 모델
- umc
- prometeus
- Spring
- Nice
- fosslight
- metricbeat
- kong
- 자료구조
- DI
- supabase
- template/callback
- 메소드
- devops
- monitoring
- Today
- Total
youngseo's TECH blog
[DB] @Transactional 이해하고 사용하기 본문
트랜잭션에 대해 이해하고 잘 적용해 나가보자 !
✍트랜잭션이란?
간단히, 데이터에 동시 접근하는 여러 프로그램들이 있을 때 데이터 정합성을 보장하기 위해 사용한다.
ACID! 원자성, 일관성, 독립성, 지속성 원칙을 따른다.
Spring에서는 어떻게 사용할 수 있을까?
Spring에서 제공해주는 TransactionTemplate로 롤백, 커밋을 구현하거나,, PlatformtransactionManager를 주입받아,, 오마이갓 이부분은 쉽게 설명할 수 없다 AOP,, 등등 코드로 구현하는 방법도 있지만 오늘은 @Transaction 어노테이션으로 트랜잭션을 사용하는 방법을 알아보자.
트랜잭션 경계설정 전략
앞에서 어떤 방식으로 트랜잭션을 구현할지 설정하고, DAO 코드를 작성했다면, 다음은 트랜잭션의 경계를 설정해야 한다. 쉽게 말해 setAutoCommit(false)로 트랜잭션의 시작을 선언하고 commit()또는 rollback()으로 트랜잭션을 종료하는 작업이라고 이해하면 쉽다.
주로 트랜잭션의 시작과 종료가 되는 경계는 서비스 계층 메소드이기 때문에 Service 단계의 클래스나 인터페이스의 메소드에 설정하는 것이 좋겠다.
@Transactional의 적용 우선순위는 클래스의 메소드 > 클래스 > 인터페이스의 메소드 > 인터페이스 순이다. 구체화될수록 우선순위가 높다.
트랜잭션 속성 설정
그렇다면 메소드별 트랜잭션 속성을 설정해보자 !
1. readonly 설정
메소드 명이 get 또는 find 같은 이름으로 시작한다면 주로 readonly=true 설정을 주는 것이 좋다.
readonly=true 속성은 변경감지를 위한 스냅샷을 유지하지 않아도 되고, 영속성 컨텍스트를 Flush하지 않아도 되기 때문에 성능 최적화 측면에서 좋다고 한다.
첨언) aop와 tx 스키마의 태그를 이용해 빈으로 경계설정을 적용한다면, get 으로 시작하는 메소드들에 공통적으로 같은 종류의 전략을 적용시킬 수 있다는 장점이 있다고 한다. 이 때, 어드바이스와 포인트컷을 사용하여 어떤 부가 기능(어드바이스)을 어떤 클래스/메소드에 적용할지(포인트컷) 안할지 적용하는 과정이 필요하다.

2. 격리(고립)수준
여러 트랜잭션이 동시에 실행될 때 데이터베이스에서 트랜잭션 간에 어떤 수준의 격리가 필요한지 설정하는 방법이다.
나는 항상 아래 표로 외우고 있다.
| Dirty Read | Non-Repeatable Read | Phantom Read | |
| Uncommitted | o | o | o |
| Committed | x | o | o |
| Repeatable | x | x | o |
| Serializable | x | x | x |
3가지 문제가 되는 Read 들에 대해 알아보자.
- Dirty Read : A 트랜잭션에서 아직 커밋되지 않았는데 B가 변경된 데이터 읽음
- Non-Repeatable Read: A 트랜잭션은 데이터를 읽고, B 트랜잭션은 데이터를 수정했다. 그리고 A가 다시 읽었다. A가 읽은 데이터가 다르다.
→ 일단 이 둘은 ‘다른 트랜잭션 / 동일한 트랜잭션(한 트랜잭션에서 값을 반복해서 읽음)’에서 ‘다른’ 데이터를 읽었다는 점에서 차이가 있다.
- Phantom Read : 커밋된 삽입. 즉, A 트랜잭션이 행의 집합을 읽고 있는데 B 트랜잭션에 의해 새로운 행이 만들어지거나 기존 행이 삭제되는 현상을 의미한다.
→Non-Repeatable과의 차이는 ‘범위 기반의 쿼리’에서 발생한다는 점에서 있다.
3. 전파 속성
만약 Service 레벨의 A 메소드 내부에서 B,C,D 트랜잭션 3개가 호출된다고 할 때, A 메소드에 @Transactional을 적용하면 어떤 요청 흐름이 발생할까?
이는 트랜잭션 전파 수준 설정에 따라 달라진다. 만약 기본 옵션인 REQUIRED를 가져간다면 로컬 트랜잭션 3개가 모두 부모 트랜잭션인 A에 합류하여 수행된다. 따라서 A,B,C,D가 모두 같은 트랜잭션이므로 어느 하나의 로직에서든 문제가 발생하면 전부 롤백이 된다.
따로 옵션을 주고 싶다면 아래의 설정방식을 정의해주면 된다.
MANDATORY의 경우, 메소드가 호출되는 시점에서 이미 실행 중인 다른 트랜잭션이 있어야 함을 의미한다. 그렇지 않으면 예외가 발생한다.
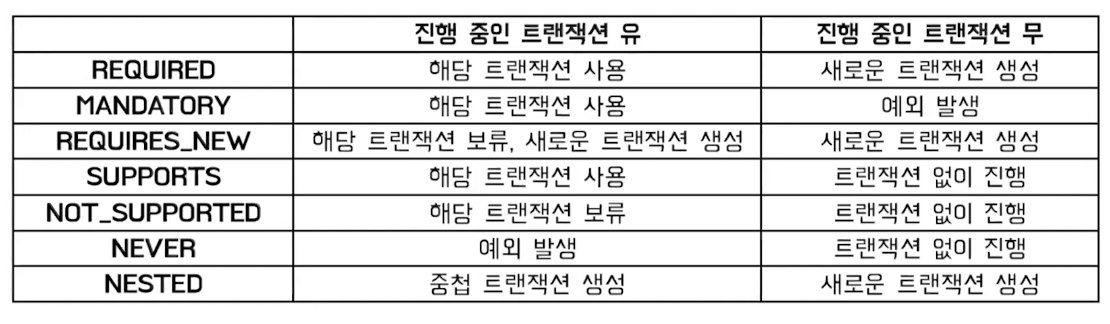
트랜잭션 롤백과 예외처리
롤백이란 트랜잭션 작업 중 문제가 발생했을 때, 트랜젝션의 처리 과정에서 발생한 변경 사항을 취소하고, 트랜잭션 과정을 종료하는 과정을 의미한다.
트랜잭션은 RuntimeException과 Error과 같은 Unchecked exception(ex. NullPointException, IndexOutofBoundException)에서는 롤백되지만, Checked exceptions(ex. IOException, FileNotFoundException, SQLException, ClassNotFindException, try/catch와 throw로 예외를 던져야 하는 exception)에서는 롤백되지 않는다는 특징이 있다.이 때 Checked exceptions를 롤백처리하려면 @Transactional에 rollbackFor 속성을 두어야 한다.
@Transactional(rollbackFor={Exception.class}) //in Checked exceptions그렇다면 내가 적용한 Transaction에 대해 살펴보자. 나는 Exception 클래스를 상속한 ResponseException을 사용하고 있다.
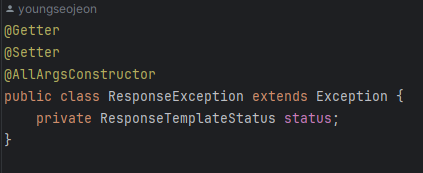
이 ResponseException을 사용하는 코드를 살펴보았다.
해당 코드에서는 로직이 간단해 데이터 변경이 발생하기 전에 이미 예외가 발생하므로 굳이 Transaction에 Exception 표시를 해줄 필요가 없어보였다.
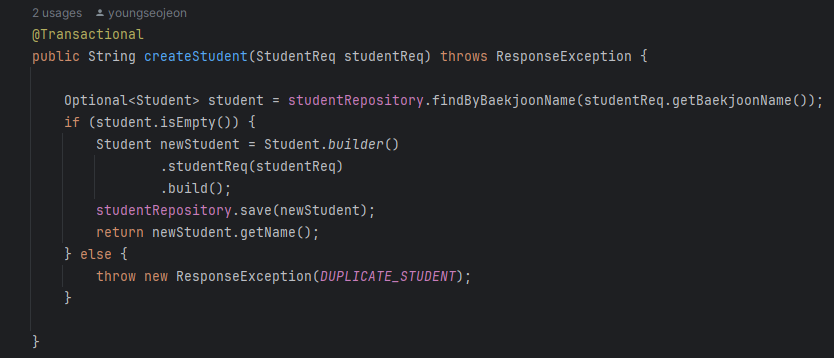
그런데 아래 로직에서는 어떨까?
weekService.createWeekList와 semesterService.addStudy 메소드를 호출하고 있다. newStudy를 저장한 이후 semesterService를 통해 study를 추가하고 있다.
만약 semesterService.addStudy 도중 ResponseException이 발생한다면 롤백되지 않는 상황을 예상할 수 있다.
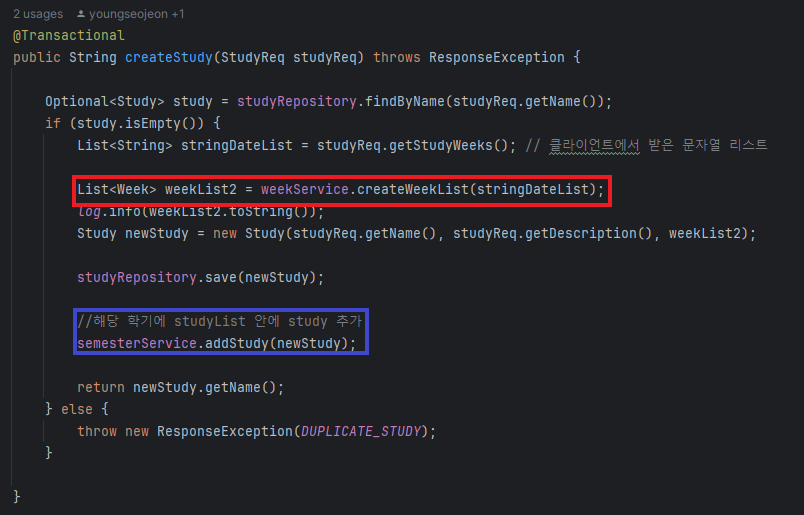
그렇다면 addStudy 메소드를 확인해보자. 다행히,, 해당 메소드에서는 DB 데이터가 아닌 단순 날짜 조회 메서드들로 이루어져 있어 Exception이 나는 상황이 존재하지 않았다. 👏
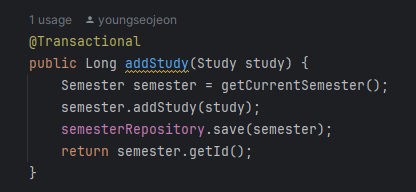
만약 Exception(을 상속한 ResponseException)이 일어나 롤백이 필요한 상황이라면 아래와 같이 해당 Exception이 일어난다면 rollback하도록 명시해주어야 한다 !! 일단 불안해서 명시해주었다 ..😬

느낀 점
@Transaction에 대해 공부하며 느낀 점은 동시접근 상황과 함수 실행 순서에 대한 이해가 중요하다는 것이다.
사실상 위에서 이야기하는 전파 속성 등도 A 함수가 B 함수를 어떻게 부르는가에 따라 달라지는 것이라, 코드 호출을 다르게 구현하는 것으로도 트랜잭션을 풀어나갈 수 있다. 동시접근에 있어서의 여러 트랜잭션 상황을 더 이해하기 위해 계좌 서비스를 구현해보면 좋을 것 같다✨
CS
ACID의 4가지 특징을 보장하는 방법에 대해 설명해보세요.
A
원자성은 all or nothing을 의미하며 한 논리적 작업단위에서 모두 실행되거나 모두 실행되지 않도록 하는 것을 의미합니다. 이를 보장하기 위해 save point를 지정해두고 트랜잭션에서 오류가 발생한다면 rollback처리하고, 정상적으로 실행된다면 commit한다는 방식을 사용합니다. -> 커밋/롤백 처리를 위해 트랜잭션 로그 파일 또는 REDO로그를 사용한다.
C
일관성이란 트랜잭션 전후에 데이터 모델의 모든 제약조건, 예를 들어 기본키/외래키 등을 만족하는 것을 통해 보장합니다. 예를 들어 Student와 Study 사이에 student_id가 foreign key라고 할 때 만약 Student 도메인에서 student_id가 UNIQUE 제약조건으로 변경되면 Study에서도 이 변경을 따라가야 합니다. 이를 trigger 등의 방법으로 적용합니다.
I
고립성이란 트랜잭션의 간섭 때문에 공통된 데이터가 다른 트랜잭션에 의해 방해되지 않도록 하는 것을 의미합니다. OS의 세마포어(semaphore)와 비슷한 개념으로 lock & excute unlock 등을 통해 고립성을 보장할 수 있습니다.
D
지속성이란 Data가 손실될 염려없이 영구적으로 반영되는 것을 의미합니다. Mysql을 포함한 많은 데이터베이스의 구현에는 트랜잭션 조작을 하드디스크에 로그로 기록하고 시스템에 이상이 발생하면 그 로그를 사용해 이상 발생 전까지 복원하는 것으로 지속성을 실현하고 있습니다. mysql 바이너리 로그 백업 -> Redo(누군가가 무엇을 했다는 정보), Undo(어떻게 하면 과거의 상태로 돌아갈 수 있는지에 관한 정보)를 이용해 복원한다.
REDO 로그는 주로 디스크에 저장된다. 이 로그는 디스크에 쓰여지지 않은 변경 내용을 추적하여 데이터베이스의 내구성을 보장한다. 즉, 트랜잭션이 커밋되면 트랜잭션 변경 내용이 REDO 로그로 기록되고 이 변경 내용은 이후에 디스크에 반영된다.
UNDO 로그는 주로 메모리, 세그먼트에 저장된다. 트랜잭션이 롤백되면 해당 트랜잭션에서 수행한 변경 내용의 역순이 UNDO 로그에 기록된다. 롤백이 필요한 경우 UNDO를 사용하여 롤백한다.
'BackEnd' 카테고리의 다른 글
| [Java|Spring] 동시성 문제 (0) | 2024.07.21 |
|---|---|
| [OS] Sync/Async, Blocking/NonBlocking (0) | 2024.01.22 |
| [Java|Spring|JSP] Koala 출석부 제작 후기 ..그리고 보완 방향! (0) | 2024.01.16 |
| [DB] RDS DB 마이그레이션 과정 - RDB와 NoSQL (0) | 2024.01.06 |
| [ELK|Python] REST API로 ES에 데이터 색인하기 (0) | 2024.01.04 |



