
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- jwt-java
- API Gateway
- kong
- konga
- DI
- umc
- 화자분리
- 파이썬
- prometeus
- fosslight
- 메소드
- curl
- pyannote
- C++
- monitoring
- ELK
- devops
- metricbeat
- Spring
- OpenSource
- docker
- roll over
- supabase
- java
- elastic search
- 자료구조
- mybatis
- Nice
- 하이브리드 데이터 모델
- template/callback
- Today
- Total
youngseo's TECH blog
[스터디 후기] 데이터 플랫폼 설계와 구축 본문
개요
이번에 사내 스터디로 진행했던 데이터 플랫폼 설계와 구축 책 내용을 정리해보았습니다. 후기에서도 볼 수 있듯이 번역본이라 힘 들여서 읽어야 하는 부분도 있긴 하나, 전반적으로 ETL 과정에서 놓치기 쉬운 부분들을 보기 쉽게 정리해두어서 공부에 도움이 많이 되었습니다 🤩

Extract: 하나 또는 그 이상의 데이터 원천들로 부터 데이터 추출
Transform: 추출한 데이터를 요구사항에 맞게 변경하는 작업
Load: 변형 단계의 처리가 완료된 데이터를 특정 목표 시스템에 적재
회사에서, 외부 업체에서 받아온 데이터들을 사내 데이터 스키마에 맞게 가져와 적재하는 프로세스를 구축하는 작업을 진행했다.
당시 작업 내용을 회고하고, 이후 다른 형태의 ETL 작업을 경험할 수도 있으니 다방면의 상황에서의 해결방법을 생각해보면 좋겠다.
ETL Pipeline
✓ 대략적인 ETL 파이프라인을 살펴보자.
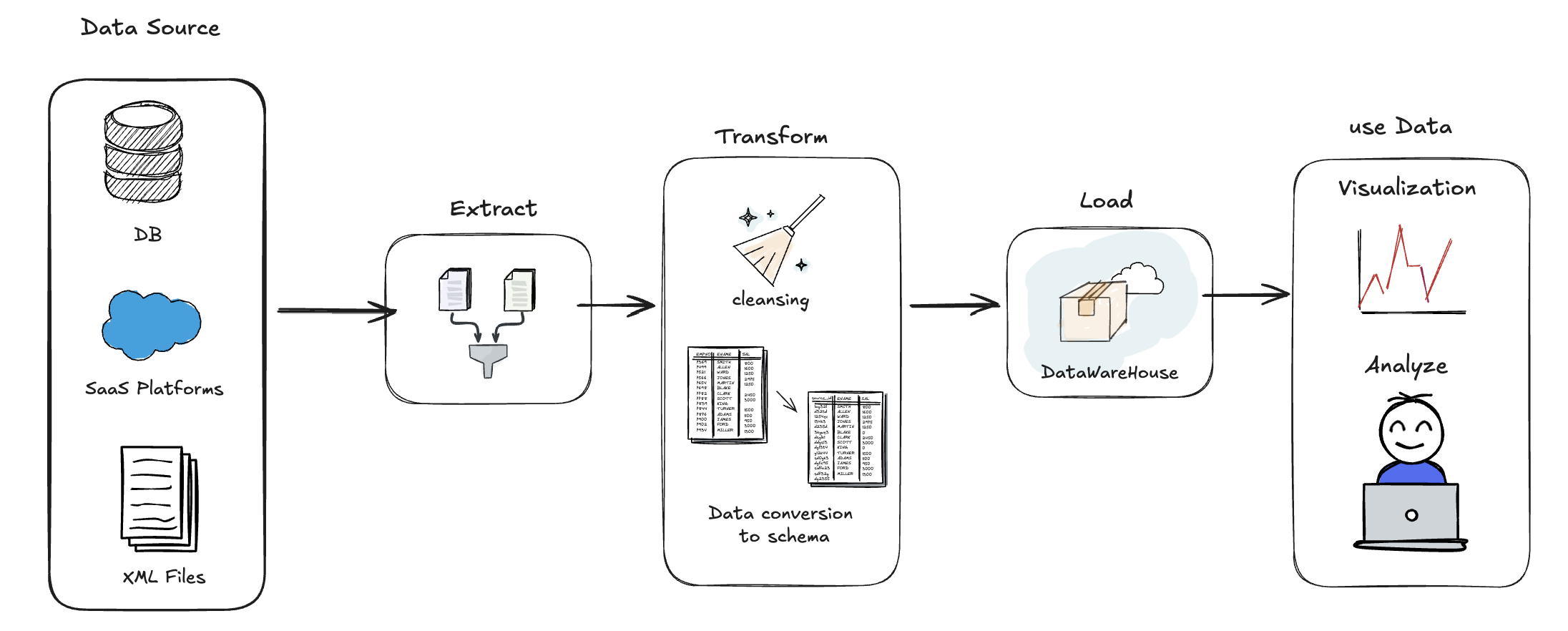
공공데이터 포털에 있는 데이터를 가져오는 상황을 가정해보자.
Extract) 먼저, 인터넷에 올라와있는 CSV 파일(Data source)을 다운로드하여 데이터를 추출(Extract)해야 한다.
Transform) 데이터들 중에는 의미없는 NaN 값도 있을 것이므로 이를 Cleansing하는 작업이 필요하다. 그리고 DB가 요구하는 스키마에 맞춰 데이터를 변형 한다.
Load) DB에 데이터를 저장한다.
Visualization) DB 데이터를 분석하고 사용한다.
✓ AWS를 사용한다면, 어떤 서비스들로 구현해볼 수 있을까?
수집 데이터 특성에 따라 아래의 두 가지(스트리밍 데이터와 배치 데이터) 갈래로 나누어 살펴볼 수 있다.
아래는 AWS 관련 예시다. AWS를 이용한 Data Pipeline 툴 선정이 필요하다면 참고하면 좋을 것 같다.
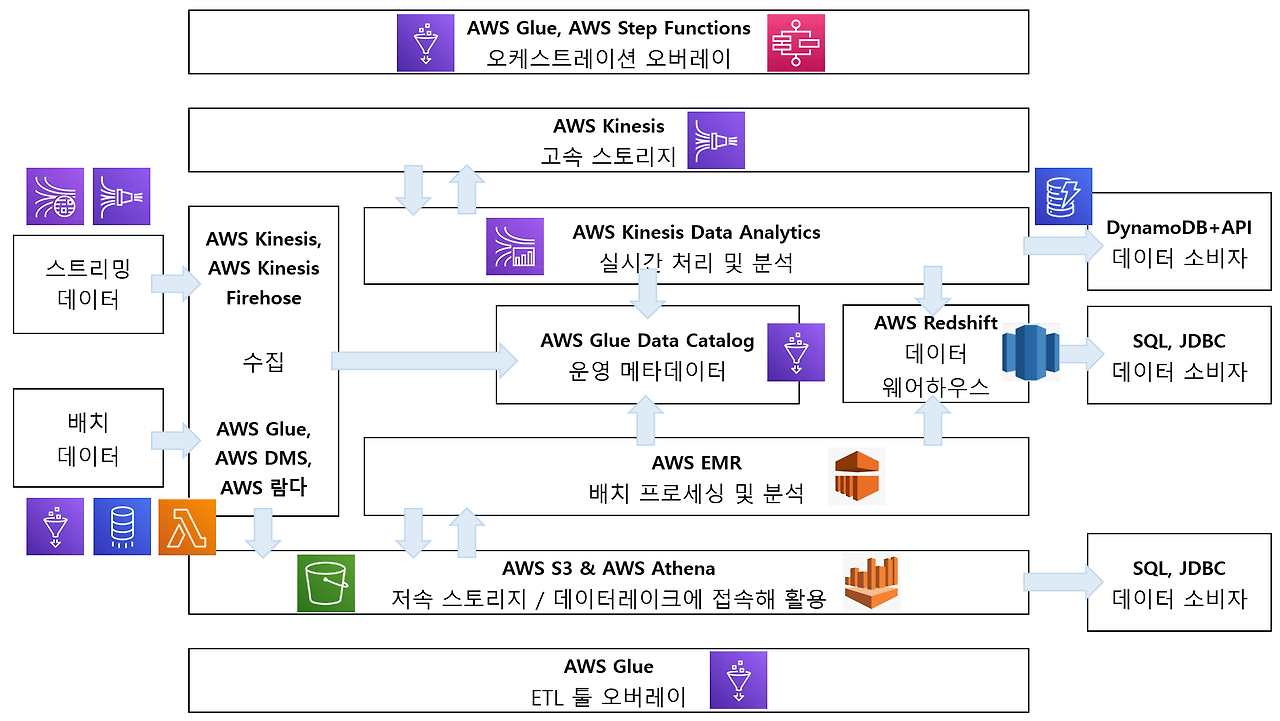
수집 단계
✓ 전체 데이터 수집과 증분 데이터 수집의 차이, 그리고 놓치기 쉬운 부분
수집 단계에서는 전체 데이터 수집과 증분 데이터 수집에 대한 고민이 필요하다. 증분 데이터란 쉽게 말해 매번 '전체 데이터'를 받는 게 아니라 '새롭게 추가되거나, 수정되거나 삭제된 데이터'를 받는 것을 의미한다.
이 책의 5장에서는 그 중에서도, 시간별 생성, 수정, 삭제에 대한 트래킹 에 대해 유심히 다루고 있다.
매주 월요일마다 A라는 쇼핑몰 사이트로부터 데이터(옷, 옷을 구매한 구매자 수)를 새롭게 수집하는 파이프라인이 있다고 가정해보자. 그런데 A 쇼핑몰 사이트에서 화요일날 Selena가 '샤랄라 원피스'를 구입했는데 수요일날 환불 처리를 하여 데이터가 그대로 +1되었다가 -1되었다고 해보자. 그러면 다음주 월요일에 증분 데이터를 받더라도, 우리 입장에서는 이 데이터의 생성/삭제 이벤트를 트래킹할 수 없으니 Selena의 '샤랄라 원피스' 구매 이력을 트래킹할 수 없다.
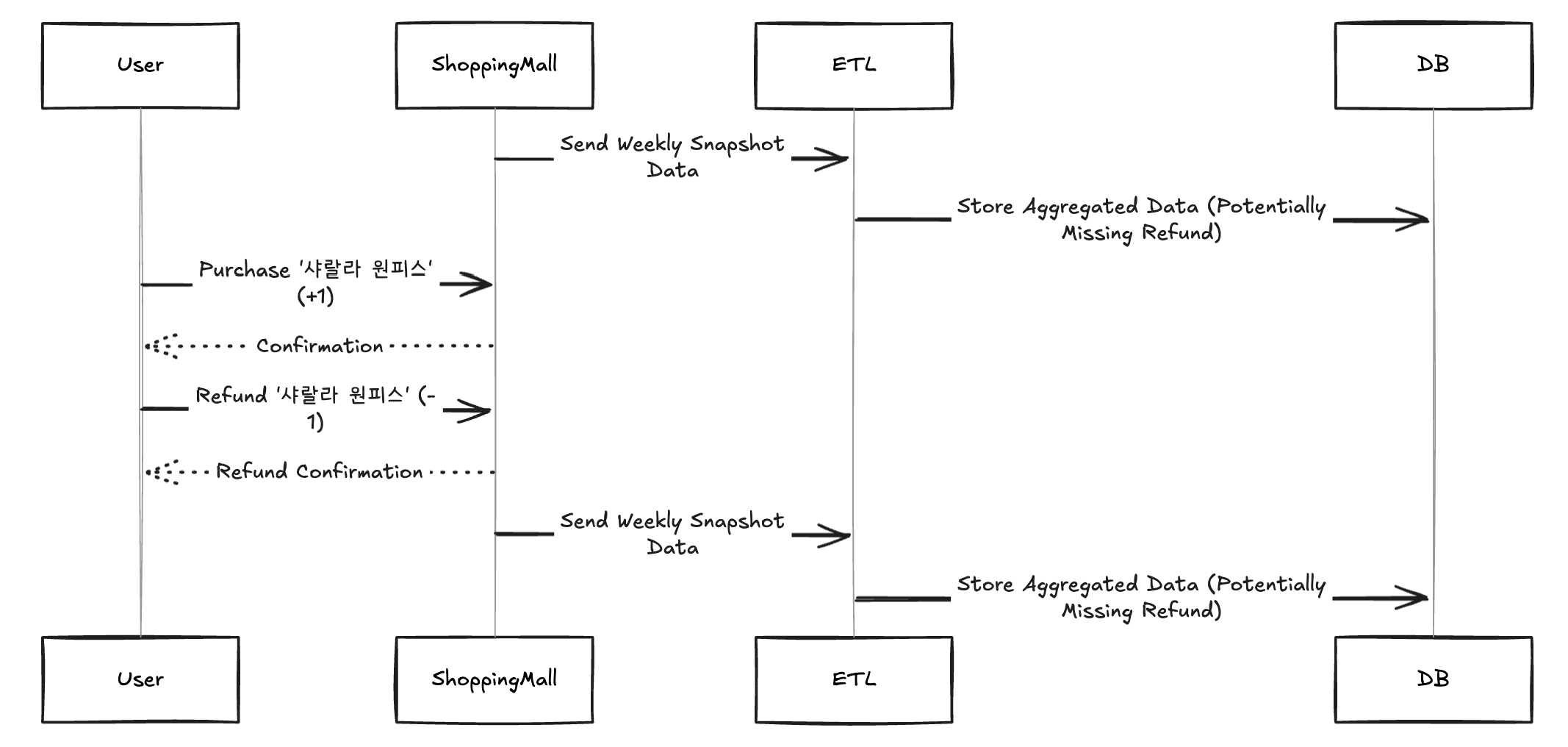
데이터 수집 파이프라인 설계 시 특정 시점의 데이터 뿐만 아니라 데이터 생성/수정/삭제 이벤트 또한 중요하다면, 시간 흐름에 따른 데이터 변화 내용도 파악할 수 있어야 한다. 위와 같은 상황에서는 A라는 쇼핑몰 사이트에게 '시간흐름에 따른 데이터 변화 내용을 스냅샷 형태로 저장해서 달라'고 요청하는 형태로 극복할 수 있다. 이 요청에서 나아가 CDC 개념에 대해서도 공부해보면 좋다.
✓ 수집 방식의 차이 - 파일 방식, 스트리밍 방식, API 방식
1️⃣ 파일 방식
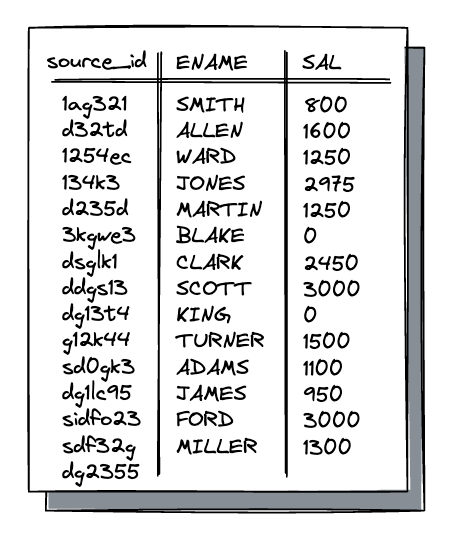
csv 파일과 같이 파일로 받는 방식이다. 주로 배치성으로 데이터를 가져오는 형태로 진행하게 된다.
스키마가 정해져있기 때문에 데이터가 예상 가능하다는 장점이 있지만, 데이터가 워낙에 대량이다 보니 I/O 비용을 고려해야 할 수 있다. 따라서 주로 최초 1회 수집에만 전체 데이터를 수집하고, 이후에는 증분 데이터만 수집하는 형태로 진행한다.
수집했던 데이터에는 '수집 처리 상태'를 체크하여 재처리를 극복할 수 있다.
2️⃣ 스트리밍 방식
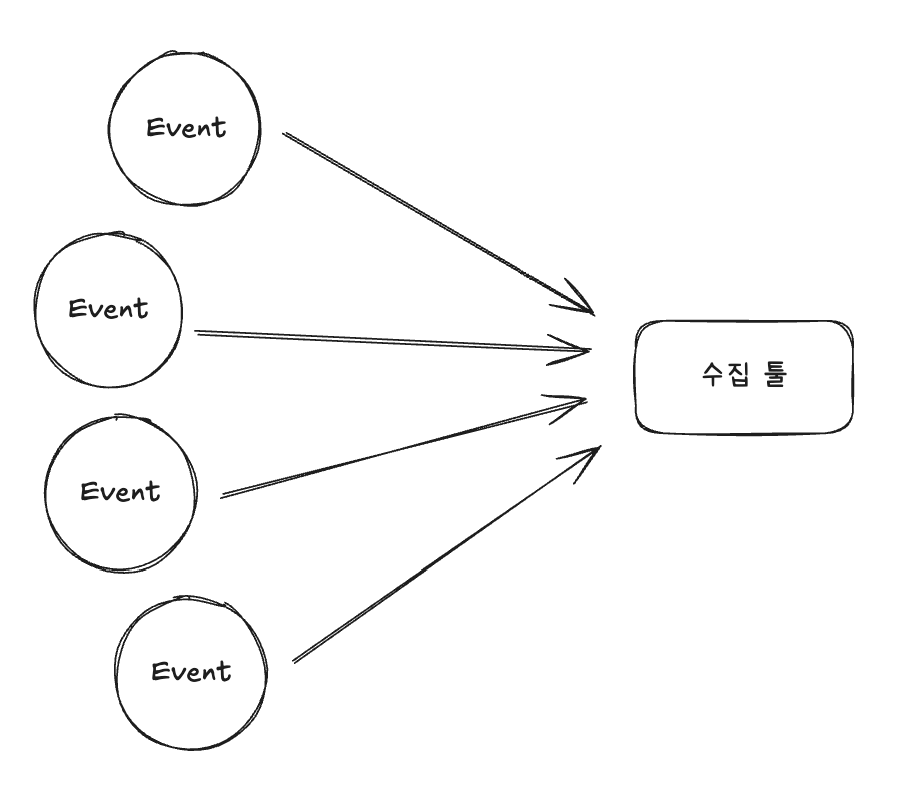
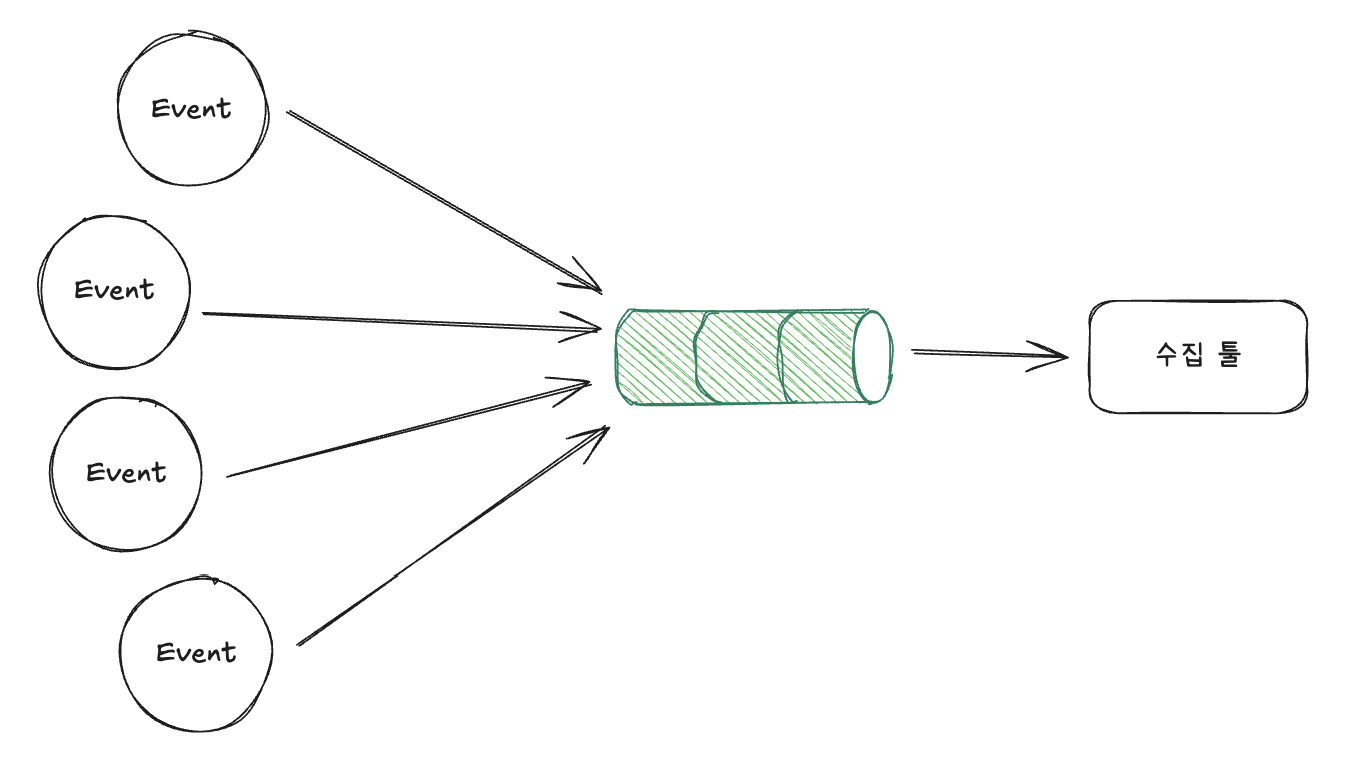
스트리밍 방식에서는 Event를 수집 툴로 직접 받게 되면 부하가 생길 수 있으니 이를 제어하기 위해 Kafka와 같은 메시징 시스템을 활용해 일시적으로 데이터를 저장해두고 처리하는 방식을 사용한다.
스트리밍 데이터의 경우에는 파일(배치) 처리 방식과 달리,
1. 중복 제거 절차를 구현해야 한다. 중복 제거의 경우 주로 메시지 고유 식별자를 활용한다.
2. 확장성을 평가해야 한다. 메시지 브로커를 놓는다고 하더라도 리소스의 한계에 도달할 수 있어 병목이 생길 수 있다.
3. 메시지 만료 정책 때문에 데이터 재처리에 더 신경써야 한다. Kafka에 메시지를 1주일간 보관한다고 가정하면 데이터를 재처리하려고 할 때 이미 데이터가 날아갔을 위험이 존재한다.
3️⃣ API 방식
API 의 경우 보안이 중요한 기업과의 데이터 교환 과정에서 많이 사용한다고 한다. http API 의 요청으로 진행하면 되기 때문에 편리해보이나, network 오류로 인해 수집 과정에서 갑자기 끊겼을 때의 재처리, Rate Limit 등 처리가 매우 힘들다.
책에서는 '현재 API 설계 방식의 표준이 없다.'라는 표현을 쓰는데, 그만큼 고려사항도 많고 관리가 쉽지 않다.
처리 단계
✓ 수집한 데이터를 클렌징하고, 스키마에 맞게 변환
이제 수집한 데이터를 운영 서버에 맞게 처리해야 한다. 운영 서버의 스키마에 맞게 변환하는 과정이 필요하다. 이 과정에서 데이터 중복이 발생하거나, 스키마에 맞지 않는 저품질 데이터가 들어올 경우에는 cleansing해주는 작업도 필요하다. 해당 데이터를 삭제하거나 빈 컬럼이 있다면 기본 값으로 매꾸어줄 수 있을 것이다.
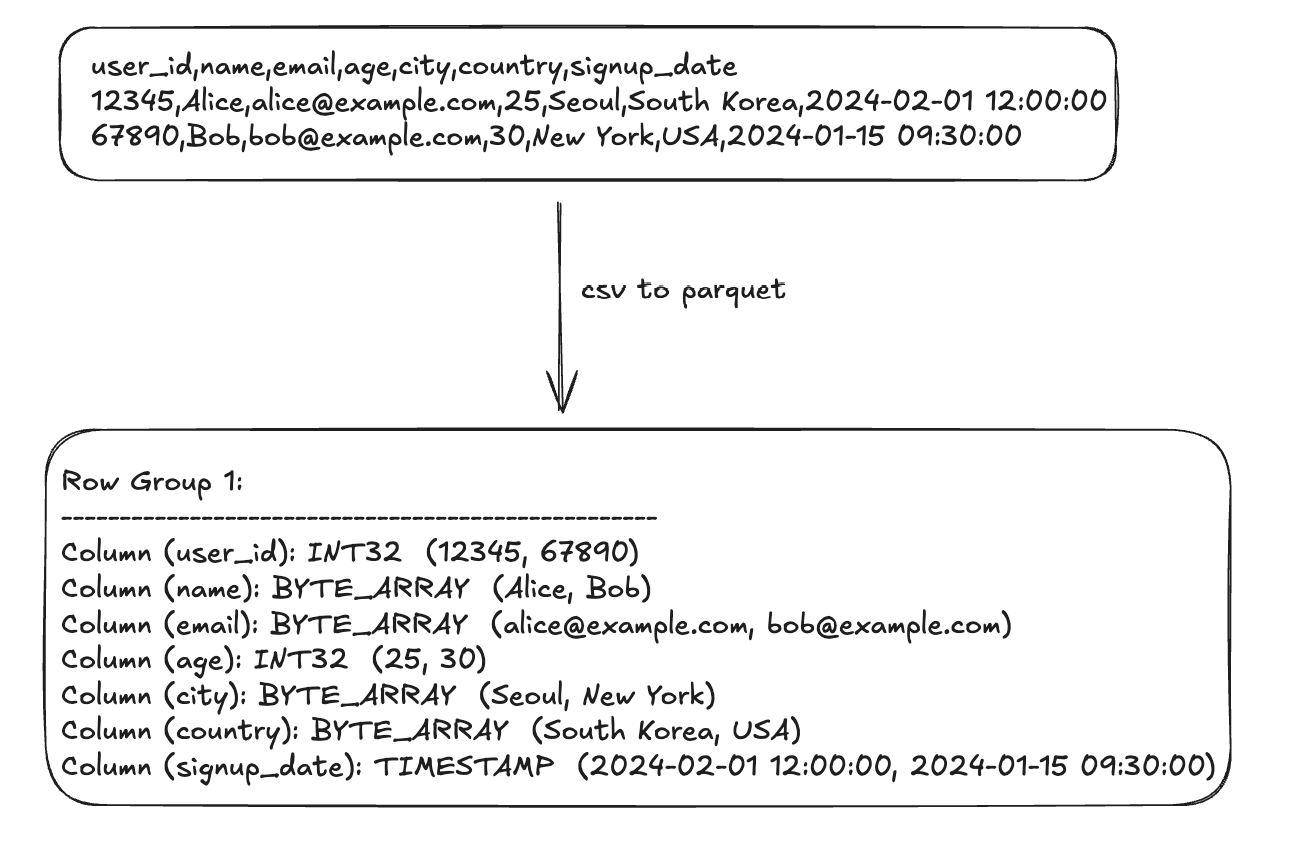
만약 수집한 데이터가 csv 파일이라면, 이 파일 포맷 또한 변경할 수 있다. 주로, 아브로 및 파케이 파일 포맷으로 변환하는데 압축률도 좋고 빠른 읽기가 가능하여 하둡 생태계에서 많이 사용한다고 한다.
저장 단계
✓ ETL에서 사용하는 데이터 웨어하우스, ELT에서 사용하는 데이터 레이크
이미 서비스하고 있는 운영 DB에 적재하기보다는, 대용량 데이터이기 때문에 데이터 웨어하우스나 데이터레이크에 적재하는 경우가 많다.
주로 ETL 과정에서 이미 Transform된 데이터를 Load하여 대용량 데이터를 분석하는 데에 사용하고자 할 때에는 데이터웨어하우스에 적재하고, ELT 과정에서 다양한 형태의 데이터를 실시간으로 저장하기 위해서는 데이터레이크를 사용한다.
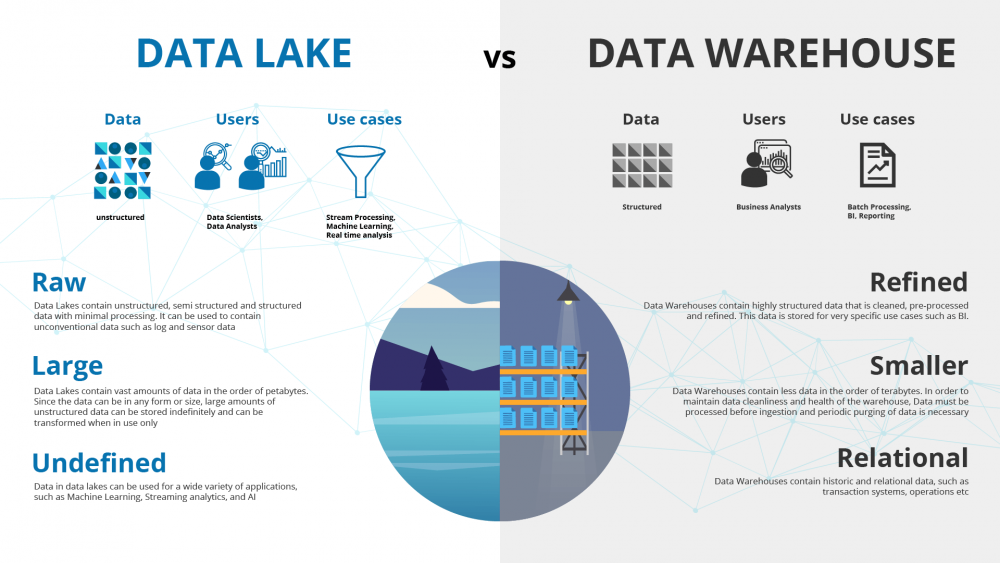
Data WareHouse의 가장 대표적인 것은 BigQuery로, 대용량 처리에 유리하고, 저렴한 비용으로 사용(사용량 기반 과금)할 수 있으며 SQL문으로 쉽게 데이터를 꺼낼 수 있다는 장점이 있다.
✓ Schema on Read vs Schema On Write
Schema On Read란, 말 그대로 데이터의 Schema 확인을 Data를 읽는 시점에서 한다는 것을 의미하고
Schema On Write란, 데이터의 Schema 확인을 Data를 쓰는 시점에 하는 것을 의미한다.
우리가 알고 있는 전통적 RDBMS에서는 엄격한 스키마를 가지고 있어 (schema on write) 데이터를 쓸 때 스키마가 정해져 있어야 했지만, 하둡이 등장함에 따라 스키마를 강제하지 않아도 된다.
이 때 Spark에서는 스키마 추론도 가능하다고 한다. 😲 물론 사람이 보는 것만큼 정확하진 않겠지만, 그래도 자동화할 수 있다는 사실이 놀라웠당 !
만약 Schema On Write 형태의 데이터를 저장한다고 하면, 스키마가 바뀔 수 있어 적재 시점에 호환 가능성을 따져보아야 한다. 이 때 아래와 같이 이전 버전 호환성 유지형/이후 버전 호환성 유지형/승격 가능 여부 등으로 따져 스키마 호환 가능성을 따질 수 있다. 요기 내용 재미있었어서 함 적어봤습니다..
- 이전 버전 호환성 유지형 : 최신 버전(v2)를 사용해, 이전에 v1으로 저장된 데이터를 모두 읽을 수 있는가?
가능한 예시 (스키마 추가 후 디폴트 값 설정)
V1 { "name": "string", "age": "int" }
V2 { "name": "string", "age": "int", "address": null } // address에 default 값 할당- 이후 버전 호환성 유지형 : 이전버전(v1)을 이용해 새버전(v2)로 작성된 데이터를 모두 읽을 수 있는가?
가능한 예시 (스키마에 컬럼 추가) V
V1 { "name": "string", }
V2 { "name": "string", "age": "int" }- 승격 (컬럼 타입 변경) ex) int -> long, float, double
분석 및 사용 단계

이제 이 데이터를 이용해서 분석도 할 수 있고, 데이터를 유저가 활용할 수도 있게 되었다. ! 분석 단계에서도 올바른 문제 정의를 통해 오류 없는, 확실한 인사이트를 얻는 것이 중요하다.
“Above all else, show the data.”
- Edward R. Tufte
대략적인 데이터 ETL 과정에 대해 짧게 알아보았다. 책에는 다른 내용도 많은데, 하둡과 관련된 분산 처리 시스템이나 AWS, Google Cloud 툴에 대해서도 자세히 나와있다. 우선은 내가 업무 진행하는 과정에서의 중요한 내용들만 뽑아서 정리해 보았고, 앞으로 시간이 있다면, Hadoop 이나 Spark 도 공부해보면 좋겠다 ~
'BackEnd' 카테고리의 다른 글
| [Java|Spring] 동시성 문제 (0) | 2024.07.21 |
|---|---|
| [OS] Sync/Async, Blocking/NonBlocking (0) | 2024.01.22 |
| [DB] @Transactional 이해하고 사용하기 (0) | 2024.01.17 |
| [Java|Spring|JSP] Koala 출석부 제작 후기 ..그리고 보완 방향! (0) | 2024.01.16 |
| [DB] RDS DB 마이그레이션 과정 - RDB와 NoSQL (0) | 2024.01.06 |



