
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- metricbeat
- java
- kong
- 메소드
- 화자분리
- umc
- konga
- mybatis
- OpenSource
- pyannote
- jwt-java
- elastic search
- template/callback
- devops
- C++
- supabase
- Nice
- 하이브리드 데이터 모델
- roll over
- Spring
- DI
- API Gateway
- monitoring
- 자료구조
- prometeus
- 파이썬
- docker
- fosslight
- ELK
- curl
- Today
- Total
youngseo's TECH blog
[OS] CPU Scheduling 본문
본 내용은 Operating System Concepts 8th Edition 번역본 책을 읽고 공부한 내용입니다.
목차
1. CPU 스케줄링
1) 목표
2) CPU-I/O burst cycle
3) CPU 스케줄링을 위한 Decision Making - 선점/비선점 스케줄링
4) CPU 스케줄링을 위한 Decision Making - Dispatcher
2. 스케줄링 알고리즘
1) 스케줄링 기준
2) FCFS
3) SJF
4) Round-Robin Scheduling
5) SRT
6) Priority Scheduling
7) Multilevel Queue Scheduling
8) Multilevel Feedback Queue Scheduling
1. CPU 스케줄링
1. CPU 스케줄링의 목표
다중프로그래밍의 목적은 CPU 이용률을 최대화하기 위해 항상 실행 중인 프로세스를 가지게 하는 데에 있다. 즉 CPU burst time은 running 상태, I/O burst time은 waiting에서 ready하는 상태를 일컫는다. 이전에는 CPU burst time은 적고 I/O burst time이 많은 그런 현상이 많았다. 이것이 결론적으로 time-sharing이 필요한 이유이다. 이에 대해 알아보자!
2. CPU-I/O burst cycle
프로세스의 실행은 CPU 실행과 입출력 대기의 사이클로 구성됨을 이해하자. 프로세스들은 이들 두 상태 사이를 교대로 왔다갔다 한다. 프로세스 실행은 CPU burst로 실행되고, 뒤이어 입출력 버스트가 발생하고, 그 뒤를 이어 CPU burst .. 등등으로 진행된다. 결국 마지막 CPU burst는 실행을 종료하기 위한 시스템 요청과 함께 끝난다.
이 CPU burst들의 지속 시간을 광범위하게 측정한 결과, 아래 그림과 유사한 빈도수 곡선을 가진다. 즉 짧은 CPU burst가 많이 있으며 긴 CPU burst는 적다. 입출력 중심의 프로그램은 전형적으로 짧은 CPU burst가 많이 있다.


이를 이용하여 우리는 CPU scheduler를 통해 준비완료 큐에 있는 프로세스들 중에서 실행될 프로세스를 선택하는 기준이 필요하게 되었다.
3. CPU 스케줄링을 위한 Decision Making - Preemptive Scheduling

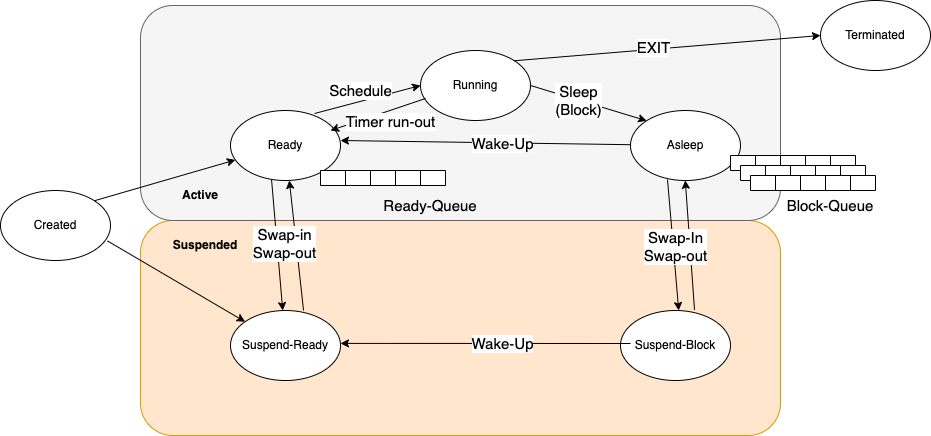
CPU 스케줄링은 다음의 네 가지 상황 하에서 발생할 수 있다.
1. 한 프로세스가 실행 상태에서 대기 상태로 전환될 때(예를 들어, 입출력 요청이나 자식 프로세스들 중의 하나가 종료되기를 기다리기 위해 wait를 호출할 때)
2. 프로세스가 실행 상태에서 준비완료 상태로 전환될 때(예를 들어, 인터럽트가 발생할 때)
3. 프로세스가 대기 상태에서 준비완료 상태로 전환될 때(예를 들어, 입출력의 종료 시)
4. 프로세스가 종료할 때
위의 상황에서 상황1과 상황4의 경우, 스케줄링 측면에서 선택의 여지가 없다. 실행을 위해 새로운 프로세스(준비완료 큐에 하나라도 존재할 경우)가 반드시 선택되어야 한다. 하지만 상황2와 3을 위해서는 선택의 여지가 있다.
즉, 1과 4에서는 non-preemptive 하기 때문에 새로운 프로세스가 할당되어야 하지만, 2, 3에서는 preemptive해야 할 수 있다.
추가적으로 설명하면 preemptive는 1.process가 created됐을 때 2.blocked된 process가 ready 상태가 되었을 때 3. timer interrupt가 발생했을 때 일어난다.
이 때에는 더 많은 오버헤드가 발생할 수 있긴 하나 CPU를 너무 긴 프로세스가 독점하는 것으로부터 막아준다. 또한 system call(예를 들어 file을 읽고 있는 중)을 하는 동안이나 OS가 불완전한 상태에 있을 때에는 스케줄링을 하지 않도록 하여 OS kernel(<-> user process)을 선점하지 않아야 한다.
이렇듯 인터럽트는 어느 시점에서건 일어날 수 있고, 커널에 의해서 항상 무시될 수는 없기 때문에 인터럽트에 의해 영향을 받는 상황에서는 반드시 동시 사용으로부터 보호되어야 한다.
4. CPU 스케줄링을 위한 Decision Making - Dispatcher
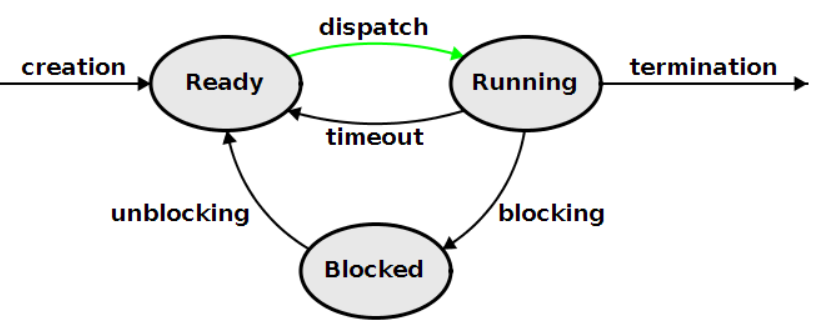
Dispatcher는 Decision making에 포함되는 또 다른 요소로, 디스패처는 CPU의 제어를 단기 스케줄러가 선택한 프로세스에게 주는 모듈이며, 다음과 같은 작업을 포함한다.
1. 문맥 교환(context switching)
2. 사용자 모드로 전환하는 일
3. 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동(jump)하는 일
준비상태(Ready)에서 실행상태(Running)로 상태전이(State Transition)하는 과정을 디스패칭(dispatching)이라고 한다. 이 dispatcher는 모든 프로스스의 문맥 교환 시 호출되므로, 가능한 한 빨라야 한다. 디스패처가 하나의 프로세스를 중단시키고 다른 프로세스를 실행시키는 데까지 소요되는 시간을 디스패치 지연(dispatch latency)이라고 한다. 이는 오버헤드를 야기시키는 큰 요인 중 하나이다.
2. 스케줄링 알고리즘
1. 스케줄링의 기준
이상적으로 스케줄링을 잘-하기 위한 여러 조건에 대해 알아보자!
먼저 User-Oriented scheduling policy goal 이다.
- 총 처리 시간(turnaround time) : 특정한 프로세스의 입장에서 보면, 중요한 기준은 그 프로세스를 실행하는 데 소요된 시간일 것이다. 총 처리 시간은 ' 메모리에 적재되기 위해 기다리며 소비한 시간+준비완료 큐에서 대기한 시간+CPU에서 실행한 시간+입출력 시간 '이다.
- 대기 시간(waiting time) : CPU 스케줄링 알고리즘은 프로세스가 실행하거나 입출력하는 시간의 양에 영향을 미치지 않는다. 스케줄링 알고리즘은 오직 프로세스가 준비완료 큐에서 대기하는 시간의 양에만 영향을 준다. 대기 시간은 준비완료 큐에서 대기하면서 보낸 시간의 합이다.
- 응답 시간(response time): 대화식 시스템에서는 총처리시간보다는 하나의 요구를 제출한 후 첫번째 응답이 나올 때까지의 시간이다. 이 때에는 예측가능성(predictability)이 중요하게 작용하며, 시스템 부하에 관계없이 프로세스는 항상 평균에 비슷한, 같은 양의 시간동안 돌아야 한다.
이와 trade-off를 가지는 System-Oriented scheduling policy goal에 대해 알아보자.
- CPU 이용률(utilization) : 위에서 말했듯 우리는 가능한 한 CPU를 최대한 바쁘게 유지하기를 원한다.
- 처리량(throughput) : CPU가 프로세스를 실행하느라고 바쁘다면, 작업이 완료되고 있는 중이다. 작업량 측정의 한 방법은 단위 시간당 완료된 프로세스의 개수로, 이것을 처리량이라고 한다.
이 외에도 fairness(process들이 모두 starvation을 갖지 않는 것), balance resources(모든 resources를 바쁘게 돌리기) 등과 같은 목표가 있다.
**아래에서 설명할 내용에 대해 간단히 보고 가자.
- 선점 - RR, SRTF, MLQ(RR+우선순위), MLFQ(MLQ+큐들 사이 이동 허용)
- 비선점 - FCFS, SJF, HRN(SJF+aging값만큼 우선순위를 갖는), 우선순위
2. FCFS (선입 선처리 스케줄링, First-Come, First-Served Scheduling)
가장 간단한 CPU scheduling으로 CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받는다. FIFO queue로 관리할 수 있다. 프로세스가 Ready queue에 진입하면, 이 프로세스의 PCB를 큐의 끝에 연결한다. CPU가 자유 상태가 되면 Ready Queue의 앞부분에 있는 프로세스에게 할당된다.
아래 그림은 FCFS 구현시 평균 대기시간(Example 1)과 FCFS의 한계(Example 2)를 보여주는 차트이다.
확실히 오른쪽에서는 그저 P1, P2, P3의 순서를 바꾸었을 뿐인데도 평균 대기 시간이 충분히 단축되었다.


FCFS의 특징
- Non-preemptive 일단 CPU가 한 프로세스에 할당되면, 그 프로세스가 종료하든지/입출력 처리를 요구하든지 하여 CPU를 방출할 때까지 CPU를 점유한다.
- Response time - slow if there is a large variance in process execution times. 한 프로세스가 지나치게 오래 CPU를 점유하여 convoy effect가 일어날 수 있다. 이는 Low CPU와 I/O device utilization을 야기한다.
- Throughput(단위 시간당 완료된 프로세스의 개수)은 안 좋을 것이다.
- Starvation은 일어나지 않는다. 어차피 순차적으로 일어나므로!
- Overhead는 적다. context switching이 거의 일어나지 않기 때문!
3. SJF(최단 작업 우선 스케줄링)
위에서 본 Example2라고 쉽게 이해할 수 있다. 똥차 하나 때문에 뒤에 스포차카들이 이 속도에 맞춰서 가야하는 convey effect를 해결하기 위해 나왔다. 하지만 SJF의 가장 치명적인 단점은 '현실적으로 말이 안된다'는 점이다. 우리가 어떤 process가 얼만큼 실행되는지에 대해 예측하기 어렵기 때문이다. 하지만 가장 이상적인 기준의 알고리즘을 해봄으로써 기준 대비 현실을 비교해보기 위해 많이 사용된다. 이 때 CPU burst/CPU blocks마다 prediction을 붙여야 한다.(과거의 CPU burst를 이용해 길이의 지속적 평균 exponential average를 파악한다)
SJF의 특징
- Non-preemptive 여기에서도 빼앗지 않고, 자기가 원한만큼은 다 준다!
- Response time - good for short processes. FCFS에 비하면 그래도 optimal하다만(평균 대기 시간을 줄여주므로), 긴 프로세스는 짧은 프로세스가 앞에서 실행이 많이 되면 그것들이 다 끝날 때까지 기다려야 한다.
- Throughput(단위 시간당 완료된 프로세스의 개수)은 높다.
- Fairness는 긴 애들이 좀 불리하다는 단점이 있다.
- Starvation은 long process들에게 조금 있을 수 있다.
- Overhead는 조금 높을 수 있다. 왜냐하면 CPU burst time을 recording/estimating 할 때, 즉, 각 프로세스들이 얼마 정도의 시간을 할애할지에 대해 estimating해야 하므로 높다.
여기에서 만약 동적으로 더 짧은 것들이 들어오면 context switching한다면 이는 SRTF에 해당한다.
4. Round Robin Scheduling
RR 스케줄링은 특별히 시분할 시스템을 위해 설계되었다. 이는 FCFS 스케줄링과 유사하지만 시스템이 프로세스들 사이를 옮겨다닐 수 있도록 선점이 추가된다. 시간할당량(time quantum) 또는 시간 조각(time slice)이라고 하는 작은 단위의 시간을 정의한다. time quantum은 주로 10에서 100밀리초 동안이며 ready queue는 원형큐로 동작한다. CPU 스케줄러는 ready queue를 돌면서 한 번에 한 프로세스에게 한 번의 time quantum동안 CPU를 할당한다.
HOW?
ready queue를 프로세스들의 FCFS 큐로 유지한다. 새로운 프로세스들은 ready queue의 꼬리에 추가된다. CPU 스케줄러는 ready queue에서 첫번째 프로세스를 선택해 한 번의 time quantum 이후에 인터럽트를 걸도록 타이머를 설정한 후, 프로세스들을 dispatch한다.
Round Robin 특징
- Preemptive 타임퀀텀 때문에 쫓겨날 수 있다.
- Response time 짧은 프로세스들에게 좋다. 긴 프로세스들은 n*q(퀀텀) 만큼의 시간동안 기다려야 할지도 모른다.
- throughput - time slice에 따라 결정된다. 적절한 time quantum을 정해야 한다. time slice가 너무 적으면 context switch가 너무 자주 일어나고 너무 크면 FCFS와 동일해진다.
- fairness는 I/O bound process에게 제약이 있는것처럼 나타난다. 즉 I/O bound process가 CPU에서의 실행시간을 모두 사용하지 못하고 I/O 작업을 수행하는 동안 일부 시간이 낭비될 수 있다.
- Starvation은 일어나지 않는다. 무조건 한 번씩 다 time quantum을 가지므로.
- overhead는 낮다. 기계적으로 다음거 돌리고 .. 이런 식으로 진행되기 때문에 priority based대비 상대적으로 오버헤드가 낮다.
time quantum과 context switching은 서로 반비례 관계일 수 밖에 없다! time quantum이 너무 길다면 프로세스들의 cpu burst가 time quantum 한 개보다 더 짧게 일어나 자동으로 빠져나오는 수가 늘어날 수 있다. 하지만 너무 짧다면 프로세스들이 interrupt를 더 자주 받게 될 것이다.
5. SRT (Shortest-Remaining-Time)
SRT는 SJF의 preemptive한 버전이다. 즉 동적으로 생각해보았을 때, 새로 도착한 process의 CPU burst가 현재 돌고 있는 process의 remaining time보다 적으면 기다리지 않고 선점시켜버린다.
SRT 특징
- Preemptive 빼앗을 수 있다.
- Response time은 좋은 편이다. process가 동적으로 할당될 때 평균 waiting time을 최소화해준다.
- Throughput은 높다. 짧은 거 먼저 실행하므로
- Fairness은 긴 프로세스들에게 패널티가 주어진다. 그래도 긴 애들도 서서히 짧아질 수 있다는 특징이 있다. (선점되기 전에 실행될 수 있으므로)
- Starvation은 있을 수 있다. 긴 프로세스들에게 특히나 있을 수 있다.
- overhead는 클 수 있다. 잔여 시간을 계속 계산해주어야 하므로!
6. Priority Scheduling
우선순위는 내부적/외부적으로 정의될 수 있다. 예를 들면 메모리가 조금 필요한 애부터, CPU를 덜 사용하는 애부터, I/O를 덜 사용하는 애부터 시작하도록 정의시킬 수 있다. 사실상 위에서 본 SJF도 일종의 priority가 존재한다고 볼 수 있다 (1/다음 CPU burst time이 priority의 기준이다).
priority scheduling은 선점형이거나 비선점혀이 될 수 있는데, 프로세스가 ready queue에 도착하면, 새로 도착한 프로세스의 우선순위를 현재 실행 중인 프로세스와 비교하여 선점해버리는 방법이 있고, 단순히 준비완료 큐의 머리 부분에 새로운 프로세스를 넣는 비선점형 방식이 있다.
우선순위 알고리즘의 가장 큰 문제는 starvation인데, 계속 priority가 높은 애들만 들어와서 걔네만 실행되어 낮은 우선순위 프로세스들이 CPU를 무기한 대기하는 경우가 발생할 수 있다.
이 문제에 대한 한 가지 해결방법은 aging이다. aging이란 오랜 시간 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증가시키는 방법이다. 예를 들어, 우선순위가 127(낮음)에서 0(높음)까지의 범위라면, 우리는 매 15분마다 대기 중인 프로세스의 우선순위를 1씩 증가시킬 수 있을 것이다. 결국 초기의 우선순위가 127이었던 프로세스도 시스템에서 쭉쭉 우선순위가 시간에 따라 올라가 0이 되는 데에 32시간 밖에 걸리지 않는다.
7. Multi Queue Scheduling
다단계 큐 스케줄링은 ready queue를 다수의 별도의 큐로 분류한다. 일반적으로 프로세스들은 메모리 크기, 프로세스의 우선순위 혹은 프로세스 유형과 같은 프로세스 특징에 따라 한 개의 큐에 영구적으로 할당된다. (아래 그림을 참고하자!) 각 큐는 자신의 스케줄링 알고리즘을 가지고 있다. 예를 들어 foreground와 background 프로세스들을 위해 별도의 큐를 사용할 수 있다. 어떤 큐는 RR 알고리즘에 의해 스케줄되지만 또 다른 queue는 FCFS 알고리즘에 의해 스케줄될 수 있다.
아래에서 볼 수 있듯 큐와 큐 사이에 스케줄링도 반드시 있어야 하며, 일반적으로 위의 프로세스들이 아래의 것들보다 높은 우선순위를 갖는다. 이 때 preemptive한 성격을 가지고 있어, 일괄처리 프로세스를 수행하던 중 대화식 프로세스가 끼어들게 되면 자리를 양보해주어야 한다.
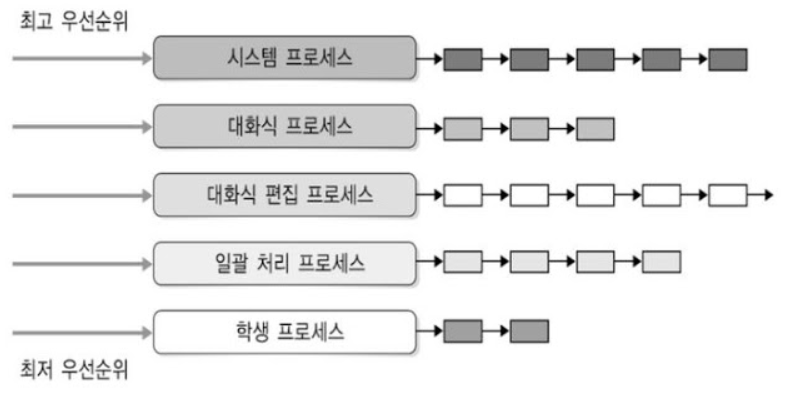
또 다른 가능성은 큐들 사이에 시간을 나누어 사용하는 것인데, 각 큐는 CPU 시간의 일정량을 받아 자기 큐에 있는 다양한 프로세스들을 스케줄할 수 있다. 예를 들어 시스템 프로세스는 CPU 시간의 80%를 할당받고 일괄 처리 프로세스는 20%를 할당받아서 프로세스들을 스케줄할 수 있다.
8. Multilevel Feedback Queue Scheduling
위에서 본 다단계 큐 스케줄링 알고리즘에서는 일반적으로 프로세스들이 시스템 진입 시에 영구적으로 하나의 큐에 할당되고 다른 큐로 이동할 수 없다. 왜냐하면 프로세스들이 포그라운드와 백그라운드의 특성을 바꾸지 않기 때문이다. 이는 스케줄링의 오버헤드가 적긴 하나 융통성이 적다는 단점이 있다.
하지만 Multilevel Feedback Queue Scheduling에서는 프로세스가 큐 사이를 이동하는 것을 허용한다. 여기에서는 프로세스들을 CPU 버스트 성격에 따라서 구분한다! 어떤 프로세스가 CPU를 너무 많이 사용하면 낮은 우선순위 큐로 이동시킨다. 이것은 위에서 본 aging과 비슷한 방법으로 starvation을 예방한다.
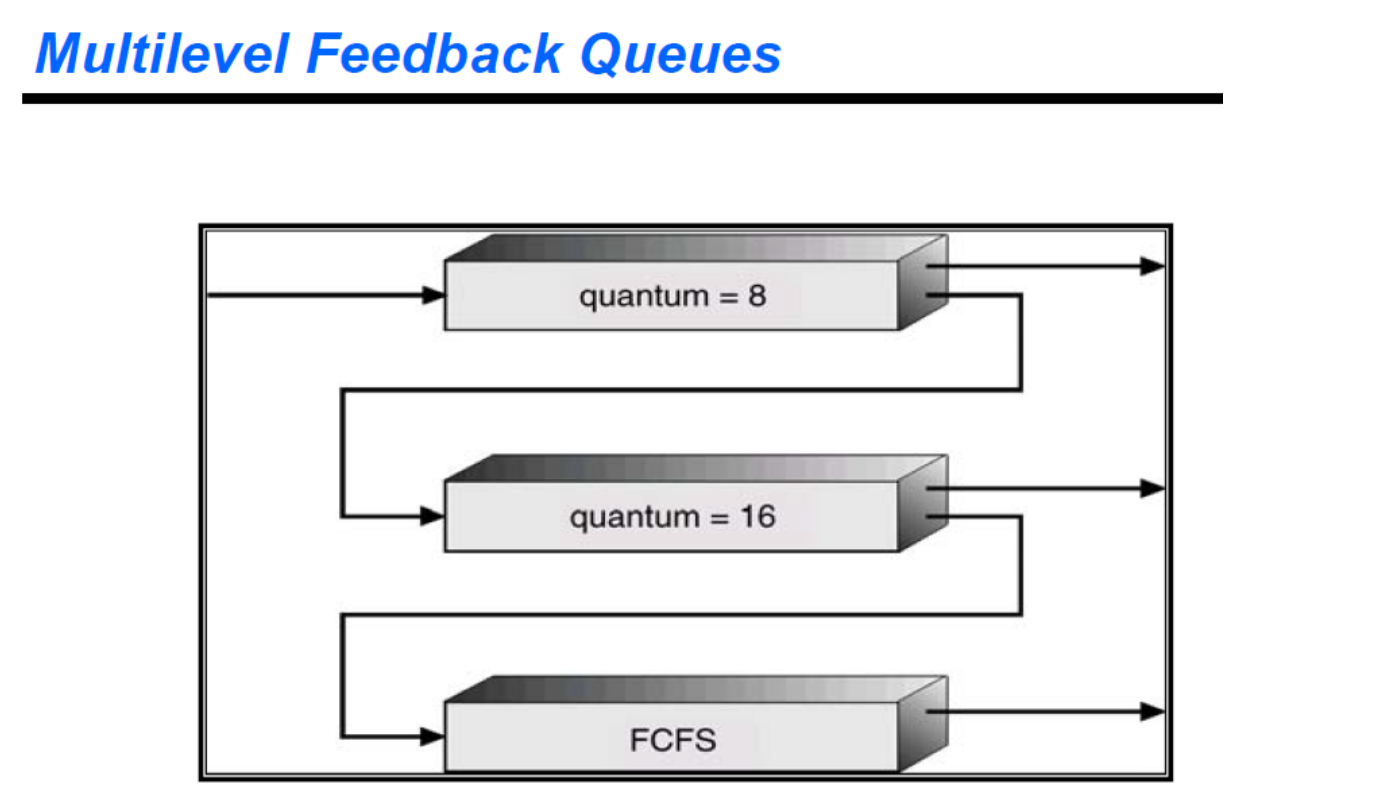
위의 사진을 참고해보자. 스케줄러는 처음에 큐 0의 모든 프로세스들을 실행시킨다. 큐 0이 비어있을 때만 큐 1에 있는 프로세스들을 실행시킨다. 마찬가지로 큐 0과 1이 비어 있을 때만 큐 1에 있는 프로세스들을 실행시킨다.
그럼 과정을 살펴보자. Ready Queue에 들어오는 프로세스는 큐 0에 넣어진다. 큐 0에 있는 프로세스는 8밀리초의 time quantum이 주어진다. 만약 프로세스가 이 시간 안에 끝나지 않으면 아래로 내려간다. 여기에서도(16밀리초) 완료되지 않으면 아래로 내려가고 이 프로세스들은 이후 FCFS 방식으로 실행된다.
이 스케줄링 알고리즘은 CPU 버스트가 8밀리초 이하인 모든 프로세스에게 최고의 우선순위를 부여한다. 이러한 프로세스는 빨리 CPU를 할당받아서 CPU burst를 끝내고 다음의 I/O burst로 간다. 8~24 밀리초가 필요한 프로세스들은 더 짧은 프로세스들보다는 낮은 우선순위를 받지만 그래도 그 다음 우선순위이다. 그 다음 긴 프로세스들은 FCFS 기준으로 처리된다.
사실은 위의 process보다는 ..thread 방식
사실 OS 시스템은 위와 같은 process가 아닌 thread 기반으로 구현된다. 따라서 thread scheduling이 중요하다. 이 때에도 user process가 아닌 kernel thread를 대상으로 처리한다.
Real time operating system의 핵심은주어진 시간 내에 task를 완료할 수 있는가 이다. soft realtime과 hard realtime으로 성격이 나뉘게 되는데, soft realtime은 작업의 시간 제약이 존재하지만, 이를 조금 넘어가는 것도 허용하는 운영체제를 의미하고, hard realtime은 작업의 시간제약을 엄격하게 지켜야하는 운영체제를 말한다. 따라서 priority를 엄격하게 지켜야 한다.시스템의 특성과 요구사항에 따라 OS 시스템을 구현해야 한다!
'CS > OS' 카테고리의 다른 글
| [OS] 메모리 관리 (0) | 2023.06.12 |
|---|---|
| [OS] Deadlock (2) | 2023.06.09 |
| [OS] 프로세스 동기화 (0) | 2023.04.13 |
| [OS] 다중 스레드 프로그래밍 (0) | 2023.04.12 |
| [OS] 프로세스 간 통신 IPC (0) | 2023.04.11 |



