
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- mybatis
- supabase
- 메소드
- DI
- umc
- ELK
- C++
- 파이썬
- OpenSource
- monitoring
- devops
- 자료구조
- metricbeat
- 화자분리
- Spring
- template/callback
- jwt-java
- roll over
- konga
- fosslight
- 하이브리드 데이터 모델
- docker
- curl
- prometeus
- Nice
- java
- pyannote
- elastic search
- API Gateway
- kong
- Today
- Total
youngseo's TECH blog
[OS] 메모리 관리 본문
본 내용은 Operating System Concepts 8th Edition 번역본 책을 읽고 공부한 내용입니다.
목차
1. 메모리 관리의 개념 및 목표
1) Classifying information stored in memory
2) segments of a process
3) 주소의 할당
4) 논리 vs 물리 주소 공간
2. Swapping
3. Linking
4. Loading
5. Running the program
1) Static Memory Allocation
2) Dynamic Memory Allocation
6. Multiprogramming - Goals in Sharing the Memory Space
1) Static Relocation
2) Dynamic Relocation
7.Paging
1) 페이징 도입 배경
2) HOW?
3) segmentation 대비 paging의 장단점
2) 페이징 우수성
3) Demand Paging
4) Page Faults
5) page table에 대해 더 알아보기
8. TLB
1) TLB 도입 배경
2) TLB란?
3) TLB를 사용한 주소 반환 과정
9. 페이지 교체
1) Page Replacement
2) Thrashing
1. 메모리 관리의 개념 및 목표
1. Classifying Information Stored In Memory
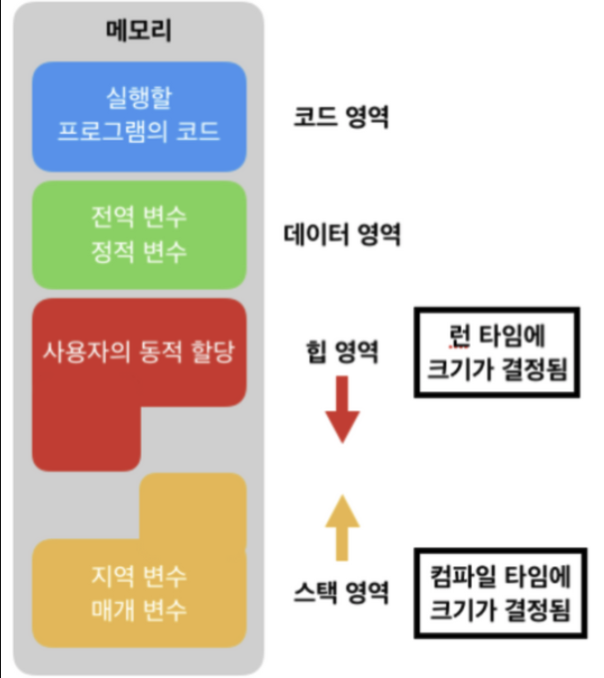
위에서 볼 수 있듯 우리는 여러 메모리 장치를 활용하여 메모리를 관리할 수 있다.
메모리를 사용하여 정보를 분류하는 기준은 다양하다.
- 프로그램 속 역할
program instructions(unchangeable)는 text segment 에 저장된다.
constants(unchangeable)인지에 따라 다르게 저장된다. 예를 들어 pi, maxnum ..등이 존재한다.
variables(changeable)도 특징에 따라 다르게 저장되는데, Local variables는 stack에, function parameters는 stack에, malloc이나 new로 할당되는 변수들은 heap에 저장된다.
참고!
heap vs bss
heap은 동적할당(주로 malloc)으로 할당된 변수를, bss(data)는 초기값 없는 전역변수를 저장해둔다. - Protection status
만약 Readable 할 수 있고 writable 하다면 variables로, Read-Only 상로 사용된다면 code, constants로, 그리고 data나 code를 공유하는 것이 중요한가에 따라 나뉜다. - Addresses vs data
만약 프로그램이 움직인다면(재할당 swap out/in , garbage collection - new를 쓰고 delete를 안 했을 때 주로 나타난다.) 주소를 수정해주어야 한다. - 힙 영역을 너무 크게 잡으면 어떤 일이 일어날까?
힙 영역은 스택 영역과 달리 런타임 시 변수를 직접 생성하고 제거한다. 만약 메모리의 힙 영역이 너무 크면 동적 변수들이 넓은 힙 영역에 존재하고 이 참조여부를 모두 확인해야 해서 GC(Garbage Collect)의 수행시간이 길어진다는 단점이 있다. 그래서 Java JVM에서도 힙 영역을 처음부터 크게 잡지 않고 꽉 찼을 때 확장하는 방법을 사용한다.
2. segments of a process

프로세스 메모리는 text, data, bss, heap, stack 등의 논리주소로 나누어진다. 일부는 read-only이고 일부는 read-write이다. 몇몇은 compile time으로 알려져 있으며, 나머지는 프로그램이 실행됨에 따라 동적으로 바인딩된다.
위에서 볼 수 있듯이 segment table은 두 개로 나누어져 있다. base는 시작하는 위치, 그리고 해당 segment의 크기가 limit에 mapping된다.
3. 주소의 할당
프로그램은 사실상 죽어있다. 이 프로그램이 실행되기 위해서는 주 메모리에 올라와서 "프로세스"가 되어야 한다. 대부분의 시스템은 사용자 프로세스가 메모리 내 어느 부분으로도 올라올 수 있도록 지원하고 있다.
메모리 주소 공간에서 명령어와 자료의 binding은 이루어지는 시점에서 다음과 같이 구분된다.
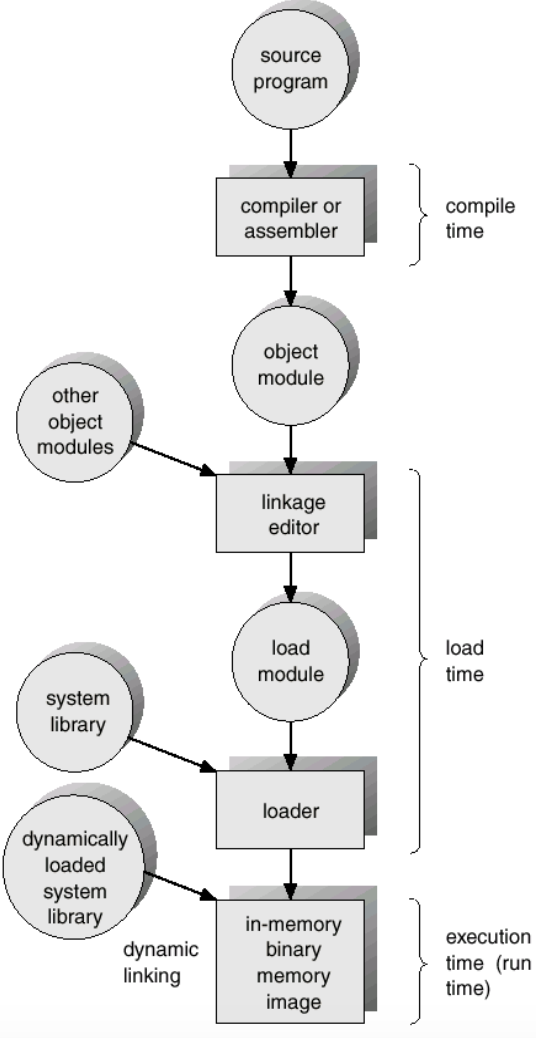
-
컴파일 시간(compile time) 바인딩 : 원시코드를 컴퓨터가 이해할 수 있는 언어로 바꾸어주는 과정
preprocessor -> compiler -> assembler -> linker의 과정을 거친다. 간단히 설명하면,
preprocessor은 전처리 라는 뜻으로, #로 시작하는 부분 #include #define을 소스코드로 바꾸어준다.
compiler은 기계어를 어셈블리어로 바꿔준다.
assembler는 어셈블리어를 기계어로 바꿔준다.
linker는 여러 object file을 하나로 합친다. -
적재 시간(Load time) 바인딩 : 데이터를 메모리로 옮기는 과정
-
실행 시간(Execution, run Time) 바인딩 : 사용자에 의해 응용프로그램이 동작되어지는 때
4. 논리 vs 물리 주소 공간
물리 주소 - 메모리가 취급하게 되는 주소, 실제 메모리 주소(하드웨어)
논리 주소 - CPU가 생성하는 주소, 프로그램/프로세스 내에서의 코드나 데이터의 주소를 의미한다. 논리 주소는 '가상(virtual) 주소'와 동일한 의미를 갖는다.
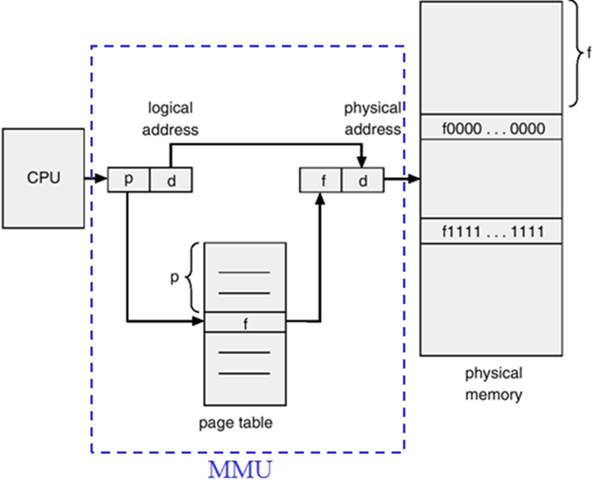
프로그램 실행 중에는 이와 같은 가상(논리) 주소를 물리 주소로 바꾸어줘야 하는데 이 변환(mapping) 작업은 하드웨어 장치인 MMU(메모리 관리기)에 의해 실행된다.
<참고>
pid[0] - 스케줄러
pid[1] - swapper
pid[2] - pager -> 커널 속에 있으면서 우리가 굳이 쓰지 않아도 알아서 돈다. invalid를 받게 되었을 때!
2. Swapping

필요한 주소 공간 전체를 메모리에 올려 두는 것이 아니라 그때그때 필요한 것들만 메모리에 올리고, 필요 없어지면 하드디스크로 내보내는 동작
3. Linking
1. Linker의 기능들
프로그램의 모든 파일들과 라이브러리들을 결합시켜준다.
각 파일들로부터 모든 세그먼트들을 재그룹시킨다. / 또 각 주소들을 서로 충돌이 안 나도록 재전송해준다.
a.o --> 0번지로 compile / b.o --> 2번지로 compile .. 이렇게 서로 충돌이 안 나도록 재전송하며 결론적으로 .exe 파일로 생성된다.
아래 그림으로 더 자세히 이해해보자!

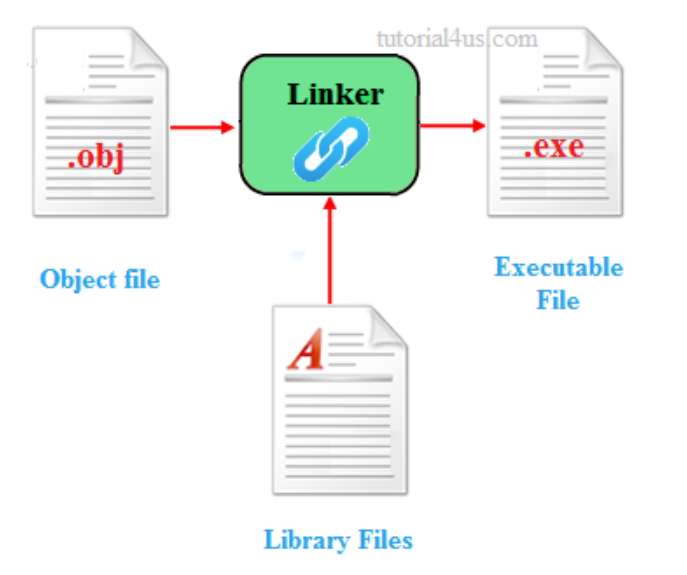
컴파일 과정에서는 각 소스 파일들(A.cpp, B.cpp)이 개별적으로 컴파일되어 오브젝트 파일(A.o, B.o)로 변환된다. 컴파일 과정에서는 소스 파일을 읽어 기계어 코드로 변환하고, 이를 오브젝트 파일에 저장한다. 이 때에는 개별 소스 파일의 의존성을 해결하지 않고 각각이 컴파일된다는 것을 주목하자!
이후 Linking 단계에서는 컴파일된 오브젝트 파일(A.o, B.o)들을 함께 결합하여 최종 실행 파일(foo.exe)을 생성한다. 링커는 여러 오브젝트 파일을 분석하고, 오브젝트 파일 간의 상호 의존성을 해결하여 실행 파일을 생성한다. 이 때 필요한 라이브러리(Library) 파일도 함께 링크될 수 있다. 링킹 과정에서는 함수나 변수 등이 정의되어 있는 위치를 찾아서 연결하고 중복되는 기호나 충돌되는 기호를 해결한다. 이렇게 모든 의존성이 해결되고 최종 실행 파일이 생성되면, 해당 실행 파일은 실행 가능한 형태로 완성된다.
.exe 파일이 생성되었다면 이제 실행 가능하다!!
그렇게 만들어진 .exe 를 까보면 다음과 같은 내용들이 포함되어 있다.

4. Loading(메모리로 이동)
이제 위에서 만든 .exe를 눌러 메모리에 로딩하는 과정을 살펴보자!
로딩이란 프로그램이 실행될 때 필요한 코드와 데이터를 메모리로 가져오는 과정이다. 이 때 실행 파일(프로그램, 라이브러리)의 코드 섹션(명령어)과 데이터 섹션(변수, 상수 등)을 메모리의 적절한 위치에 배치한다. 이 때 초기화되지 않은 변수(bss)를 위한 공간은 남겨두며, OS에는 프로그램을 로딩하는 첫번째 주소를 전달해준다.
5. Running the program(메모리 공간의 할당 문제)
1. 정적 메모리 할당(Static Allocation)
※ static이라는 말이 붙으면 보통 실행 전(=컴파일 타임)에 일어나는 일을 말한다!!!
세그먼트는 컴파일 시에 이미 할당되고 주소가 결정되기 때문에 hole이 생기지 않는다. 각 세그먼트의 크기는 미리 정해져 있으며, 컴파일러에 의해 메모리에 배치된다. 엥? 그러면 fragmentation 문제가 생기지 않는 거 아닌가? 이 개념이 너무 헷갈렸다... 뒤에서 확인!
2. 동적 메모리 할당(Dynamic Allocation)
가변 분할 기법이라고도 불리며, OS는 메모리의 어떤 부분이 사용되고 있고, 어떤 부분이 사용되지 않고 있는가를 파악할 수 있는 테이블을 유지한다.
쉽게 말해, 메모리에는 다양한 크기의 자유 공간이 여기저기 퍼져 있는데, 프로세스가 공간을 필요로 할 때 OS는 이 자유 공간들의 집합에서 적절한 것을 찾아내 여러 자유 공간 조각들을 프로세스에게 할당한다.
이 때 사용되는 자료구조의 두 가지 방법으로 Stack과 Heap이 제시된다. 둘의 차이는 다음과 같다.

이 자유 공간 리스트에서 n바이트 블록 요청을 어떻게 만족시킬지에 대한 해결책이 여러 기법들로 제시된다. 결론적으로 말하면 모의실험에서 최초>최적>최악 으로, 왼쪽에 있는 것이 더 효과가 좋았음이 입증되었다.
- 최초 적합 (First Fit)
요청을 만족시키는 충분히 큰 첫 번째 사용 가능한 가용 공간을 할당한다. 검색은 집합의 시작에서부터 하거나 지난 번 검색이 끝났던 곳에서 시작될 수 있다. 충분히 큰 가용 공간을 찾았을 때 검색을 끝낼 수 있다. - 최적 적합(Best Fit)
충분히 큰 공간들 중에서 가장 작은 것을 택한다. 리스트가 크기 순으로 되어 있지 않다면 리스트 전체를 검색해야만 한다. 이 방법은 아주 작은 hole만 만들어낸다. - 최악 적합(Worst Fit)
반대로 가장 큰 것을 택한다. 이 방식에서 할당해 주고 남게 되는 hole은 충분히 커서 다른 프로세스들이 유용하게 사용할 수도 있다. 하지만 이 때에도 리스트가 크기 순으로 되어 있지 않다면 리스트 전체를 검색해야 한다. - 최고 적합(Best Fit)
모든 메모리 공간을 검사해서 내부 단편화를 최소화하는 공간에 할당
Dynamic Allocation(동적 할당)의 경우, 세그먼트의 크기가 런타임 중에 결정되기 때문에 hole이 생길 수 있다. 메모리를 동적으로 요청하고 해제하므로, 프로그램 실행 중에 메모리 블록이 할당되고 해제된다. 이로써 세그먼트의 크기가 동적으로 변화하므로 hole이 생길 수 있다.
3. 단편화 문제
- 외부 단편화
공간 중 일부가 사용 못하게 되는 부분. 프로세스들이 메모리에 적재/제거되는 일이 반복되다보면, 어떤 hole은 너무 작아진다. 이 hole들이 여러 곳에 분산되어 있어, 전체적인 hole의 크기합은 큼에도 불구하고 연속적인 할당이 어려워지는 상황을 의미한다. -> 해결법은 압축!(page) - 내부 단편화
할당된 메모리 영역 내에서 미사용 공간이 발생하는 것으로, 분할 내부 현재 사용되고 있지 않은 메모리를 말한다. -> 해결법은 동적 메모리 할당과 같은 가변 크기 할당 방식을 사용(segment)

4. 동적 메모리 회수
WHEN?
1. 프로그래머가 메모리 할당을 해제하려는 경우 (즉, 할당된 메모리의 사용이 끝난 경우)
2. 할당된 메모리의 유효 범위를 벗어난 경우
WHY?
1. Dangling points 발생 가능 : 자기가 필요한데 필요한 메모리가 없어서 죽어버리는 현상
2. Memory leak (메모리 누수) : 메모리를 회수하지 않아 쓸데 없이 메모리를 사용하는 현상
6. Static vs Dynamic Relocation
Static은 소프트웨어로 Relocation을 구현하는 방식이고, Dynamic은 Memory Management Unit(MMU)를 사용해서 Relocation을 구현하는 방식이다.
1. Static Relocation
※ static이라는 말이 붙으면 보통 실행 전(=컴파일 타임)에 일어나는 일을 말한다!!!
정적 재배치는 실행 파일이 로드되기 전에 모든 주소를 알고 있으므로 비교적 간단하게 수행된다. 컴파일을 하면서 프로세스가 메모리 내의 어디에서 적재되어야 하는지 알려주지 않고 Logical address를 relocatable address로 만들어준 후, 컴파일 때에는 프로그램의 시작주소를 0으로 가정해 object module을 생성한다. 프로세스의 시작위치가 바뀌게 되면 reload해주면 된다.
문제점 ->
한 프로세스가 다른 프로세스의 메모리를 침범할 수 있어 safety 측면에서 좋지 않다.
process의 size가 계속해서 바뀔 수 있는 상황을 극복하지 못한다.
프로세스 run 이후 움직일 수 있는 상황을 극복하지 못한다.
2. Dynamic Relocation
실행될 때 메모리의 주소가 결정되는 것으로, logical address와 physical address가 다르다. 이에 따라 주소 번역 기능이 필요한데 이는 MMU에서 해준다. 실행되면서 Binding 된다. MMU 때문에 메모리 접근 시간은 2배로 늘어나고 오버헤드가 클 수 있다는 단점이 있지만 관리 측면에서는 효율적이다.

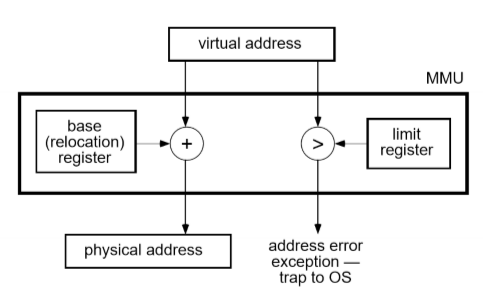
장점
- OS가 한 프로세스는 쉽게 메모리 내 다른 장소로 옮길 수 있다.
- swap in/out이 가능하다.
- OS가 프로세스가 Grow 커질 수 있도록 허용한다.
- 위치투명하다.
- memory protection, 즉 base register와 덧셈연산, limit register 를 이용해 잘못된 memory 번지를 참조하지 않도록 막아준다.
단점
- 주소의 번역이 필요하다.
- 메모리 할당이 복잡하다.
- process 가 커지면, OS는 이 프로세스를 다른 곳으로 옮겨야 한다.
- process가 물리적 메모리 크기에 제한된다.
- process는 contiguous memory 공간을 필요로 한다. (메인 이유)
3. MMU (주소 번역)
MMU는 두 개로 나뉘어져 있다. 앞에 두 비트는 text 00 / data 01 /...을 가리키는 segment를 의미하고, 뒤의 offset은 해당 segment(기준점)에서 access할 수 있는 비트 수를 의미한다. offset은 상대주소와 절대주소가 똑같이 들어온다!
Base Register -> [ 프로그램 시작주소 | 프로그램 크기 ] ----- 이런 식의 모습을 취한다.
MMU는 표 형식인데, 자기 프로세스(p1)를 돌 때에는 p1의 PCB에 존재한다. MMU가 없다면 physical address에 바로 접근해야 하는데, MMU가 도입하면서 virtual address에 접근하게 되었다. MMU를 보는 건 debugger이고, physical로 바로 접근하는 것은 OS의 역할이다.
1초에 1000번씩 context switching이 되면 쫓겨나가는 MMU는 지우고 다시 MMU를 새로 갈아치운다. 이 때 엄청 큰 오버헤드가 일어나지만 그건 어쩔 수 없다.
7. Paging
1. 배경
segmentation이란 무엇일까?
.c를 컴파일하면 아래의 4개의 segment로 분리되어 만들어진다.
.text
.data
.bss
.stack
이 때 MMU table에 채워지는 것이 loading이고 이후 자기 자리를 찾아갈 수 있다.
segmentation에서의 문제는 각각의 segment는 연속된 공간이지만 각각 T, B, D, S는 연속적이지 않다는 특징 때문이다. 그러면 나중에 한참 쓰다 보면 external segment가 남게 된다.
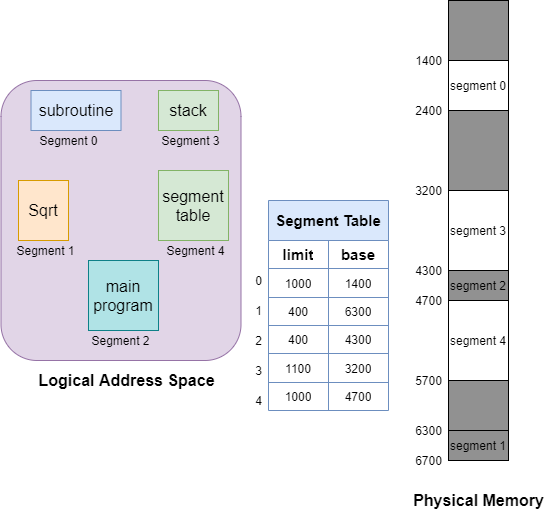
그러면 이 external segment를 없애는 방법이 없을까? 그냥 Main Memory를 똑같은 크기로 잘라놓고 가변의 segment를 mapping해서 집어넣자. 이것을 paging이라고 한다. page의 크기는 고정이다!
2. HOW? (페이지를 분할하여 할당)
--
|
|
|
|
--
이 main memory에 있는 것을 frame이라고 한다. 그러면 만약 해당 text가 124개의 frame이 필요하다고 하면 124개의 frame을 할당받는다. 그러면 124개는 연속적으로 할당하는 것이 아니라 마구마구 집어넣는다. 그러면 그걸 명시해줄 수 있는 page table(MMU와 비슷한 기능을 한다. 주소 번역!) 을 따로 표처럼 만들어서 어디에 넣었는지 명시해둔다.
여기에서 paging의 핵심은 쓰고자 하는 것이 부분적이 아닌 전체가 Main memory에 올라가야 한다는 것이다. 프로그램 시작 시 전체를 Main Memory에 올리는 과정이 loader가 loading하는 과정이다.(위에 4번 loading 설명 참고)

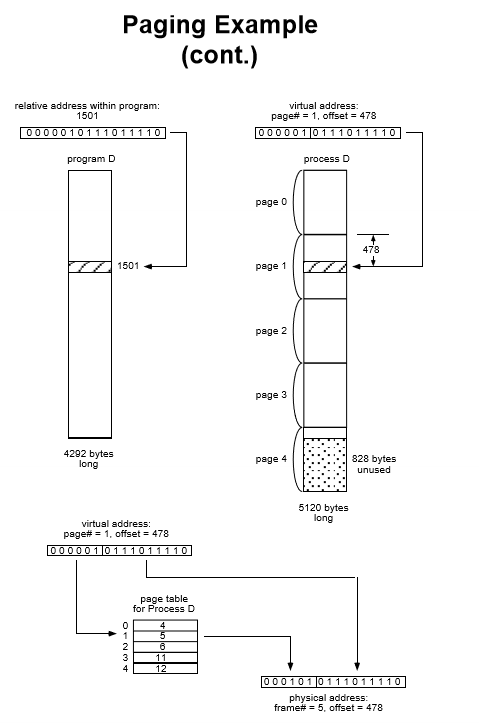
물리(physical) 메모리는 프레임이라고 불리는 고정 크기의 블록으로 나누어져 있고 논리(virtual) 메모리는 페이지(page)라 불리우는 프레임과 같은 크기의 블록으로 나누어진다.
CPU에서 나오는 모든 주소는 페이지 번호(page)와 페이지 변위(offset)의 두 개의 부분으로 나누어진다. 여기에서 페이지 번호는 페이지 테이블을 액세스할 때 사용된다.
주의 !! page table은 segmentation과 달리 한 칸이다!!
3. segmentation 대비 paging의 장단점
장점: external fragmentation 해결
단점: page 갯수가 너무 많아서 MMU table이 무지막지 커야 한다. MMU는 per-process라서 200 process가 돌면 너무 많은 MMU table이 돌아야 한다. 근데 너무 커서 이걸 main memory가 아닌 hard disk에 저장해야 한다.
이 단점을 해결하기 위해서는 storage에서 필요한 것들을 꺼내는 cache를 사용한다. pyramid의 하부는 느리고 용량이 크다. 위로 올라갈수록 속도가 빠르고 용량이 작다. 그 사이에 해당하는 캐시를 사용!
| segmentation | paging | |
| 크기 | 세그먼트 크기는 가변이다. | 페이지 크기는 고정이다 |
| 장점 | 내부 단편화를 감소시킨다. | 외부 단편화를 감소시킨다. page 개수가 많아 MMU가 커야한다. -> 이후 cache로 해결 |
| 연속적인 큰 덩어리를 왔다리 갔다리 | 조각으로 나누어 처리가 쉽다. -> swap에 유리하다. |
3-1. page와 frame의 차이?
page는 process 주소 공간의 고정 size의 logical memory 단위이고 frame은 physical address allocation 고정 size 단위이다. 한 page는 한 frame에 맞고, 어떤 페이지도 어떠한 프레임에 들어갈 수 있다. frame은 실제로 존재하는 단위이지만 page는 logical memory로 실재하지 않는다.
4. 페이징의 우수성
1. 구현이 쉽다.
2. 이식성이 높다.
3. 융통성이 높다.
4. 외부 단편화가 없다. segmentation은 연속적인 큰 덩어리가 왔다리갔다리 해서 힘들었는데 paging은 조각으로 나누었기 때문에 처리가 더 쉬워졌다.
5. 홀 선택 알고리즘을 실행할 필요가 없다. 따라서 메모리 활용과 오버헤드 면에서 매우 우수하다.
6. 물론 segmentation만의 장점도 있어 Intel은 segmentation+paging 방법을 같이 쓰다가 MMU 기술이 좋아져 only paging으로 바꾸게 되었다.
7. paging은 swap in/out에 매우 효율적이다. 아주 작은 사이즈의 swapping이 가능하기 때문이다.
5. demand paging
on demand, 즉 필요할 때에만 paging한다. 프로그램 시작 시에 프로그램 전체를 할당하지 않고, 초기에는 필요한 것들만 적재하고 이후 필요할 때마다 동적으로 할당하는 기법이다. 가상 메모리와 페이지 개념을 활용해 관리된다.
Demand paging 으로 인해 page table에 valid bit 가 추가됨
Valid bit = 어떤 페이지가 Physical memory 에 실재한다면 1, 없다면 0을 갖는 bit
사실 이 demand paging 은 real time system에서는 쓰지 못해 한정적으로 사용한다.
6. Page Faults
런타임에 일어난다(중요한 전제이다. CPU가 찾을 때 일어난다는 점!). 사용자가 요청한 페이지가 swap out 되었거나 아직 메모리에 로딩되지 않아서 없는 경우 Page-fault 가 발생한다. 그러면 해당 프로세스의 명령어 수행을 중지(Trap을 발생)시키고, 디스크에서 해당 페이지를 로딩한 뒤 명령어를 재시작해야 한다. (Trap = Software interrupt)
page fault를 줄이기 위해 preparing 방법을 사용한다. 수치적 근거에 의하면 한 시간당 비슷한 구간에서의(locality of reference) 사용이 빈번하더라. 그러니까 이제부터는 page를 가져올 때 주변 것들을 가져와서 page fault를 줄인다. 하지만 이 때 memory pollution이 발생할 수 있다는 단점이 있다.
page Faults 과정

(1) CPU가 가상 주소를 MMU에게 요청하면,
(2) MMU는 먼저 TLB로 가서 그 가상주소에 대한 물리주소가 캐싱돼 있는지 확인한다.
(3) TLB에 캐싱된 물리주소가 - 있으면 MMU가 해당 페이지의 물리 주소로 데이터를 갖고 와서 CPU에게 보내고 - 없으면 MMU가 CR3 레지스터를 가지고 물리 메모리에 해당 프로세스의 페이지 테이블에 접근한다.
(4) MMU가 페이지 테이블에서 물리주소가 있는지 valid bit를 확인한다.
(5) valid bit의 값이 - 1이면 MMU가 해당 페이지의 물리 주소로 데이터를 갖고 와서 CPU에게 보내고 - 0이면 MMU가 페이지 폴트 인터럽트를 운영체제에 발생시킨다.
(6) 운영체제는 해당 페이지를 저장공간에서 가져온다.
(7) 운영체제는 저장공간에서 가져온 데이터를 메모리에 올려주고, 페이지 테이블을 업데이트 해준다. valid bit -> 1, 물리주소 업뎃
(8) 운영체제는 CPU에게 프로세스를 다시 실행하라고 한다.
(9) CPU는 다시 MMU에 가상 주소를 요청한다.
7. page table에 대해 더 알아보기
page table은 일단 메모리에 있다. (뒤에 설명하지만 MMU는 TLB라는 캐시에 저장된다.)
MMU 내부에 page table의 위치를 나타내기 위한 레지스터가 별도로 존재한다.
page table에도 한계가 있을까? 사실상 limit이 필요없다. 어차피 자기 process에 대한 내용들을 PCB에 저장하기 때문이다. 포인터만 PCB에 연결되어 있고 MMU table은 다른 곳에 존재한다. 이는 page table과 PCB가 분리되어 있음을 뜻해 page table은 프로세스 실행 동안 물리 메모리에 '상주'하지 않아도 된다.
8. TLB

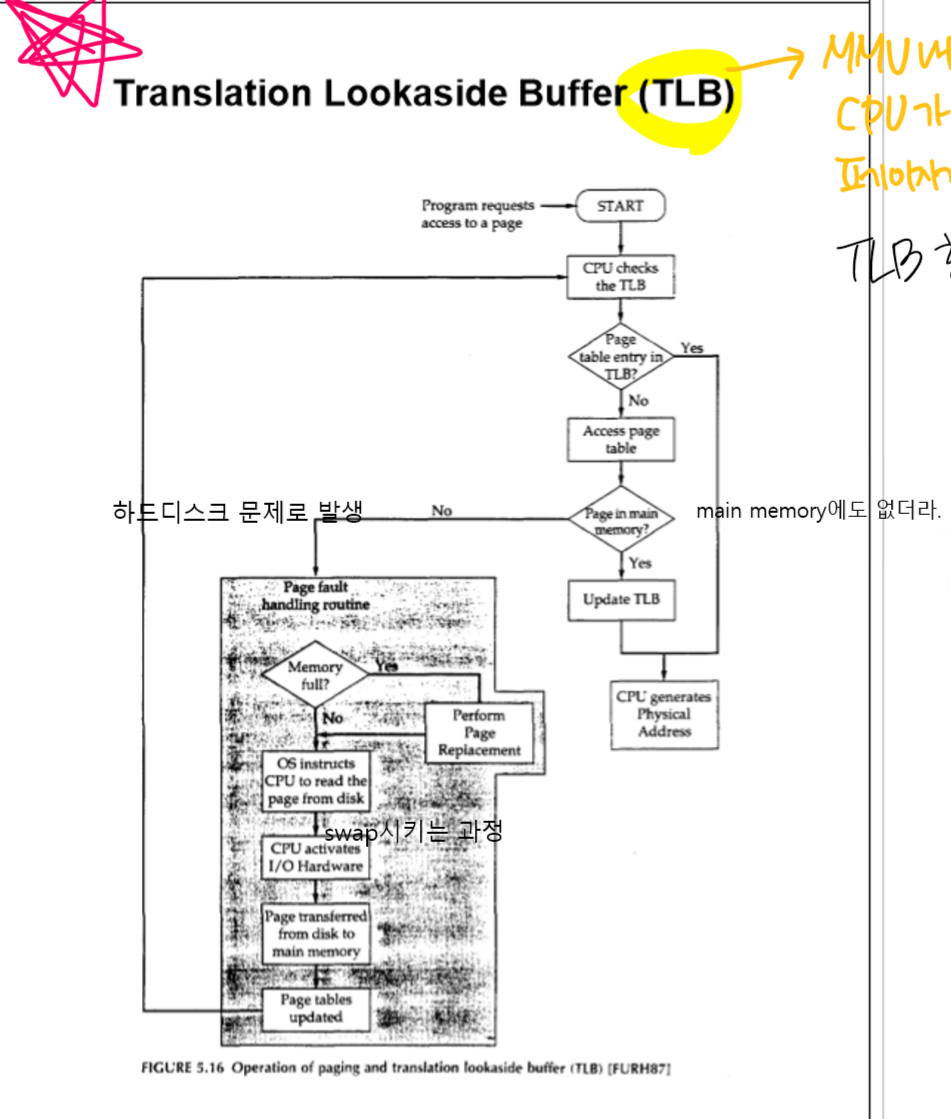
1. TLB 도입 배경
위 사진과 같은 과정을 거치니까 너무 비효율적이어서 TLB라는 캐시를 하나 놓고 이를 거쳐 사용한다. TLB hit이 발생하는가/안하는가로 달라진다.
.2. TLB란?
TLB는 MMU 내에 두는 것으로, CPU가 최근에 액세스한 페이지 번호와 페이지가 적재된 프레임 번호의 쌍을 저장하는 캐시 메모리이다. 즉 TLB 항목 = [페이지 번호 p, 프레임 번호 f]
3. TLB 를 사용한 주소 반환 과정
1. 프로세스 실행: 프로세스가 실행되면, 가상 주소를 사용하여 메모리에 접근하려 한다.
2. 가상 주소 변환: MMU는 가상 주소를 받아 가상 페이지 번호(Virtual Page Number)와 오프셋(Offset)으로 분리한다.
3. TLB 조회: MMU는 TLB에 가상 페이지 번호를 조회하여 이것에 대응하는 물리 페이지 번호를 찾는다.
엔트리를 찾으면 TLB hit로, 물리 페이지 번호를 얻지만, 없다면 TLB miss가 발생한다.
4. TLB 히트: TLB 히트라면, MMU는 TLB에서 얻은 물리 페이지 번호와 오프셋을 결합해 물리 주소를 생성한다. 이후 프로세스는 해당 물리 주소로 메모리에 직접 접근한다.
5. TLB 미스: MMU는 페이지 테이블을 참고하여 가상 페이지 번호에 대응하는 물리 페이지 번호를 찾는다. 이후 TLB에 해당 엔트리를 저장하여 이후 재사용할 수 있도록 한다. 이제 물리 주소를 찾을 수 있어 메모리에 접근한다.
9. 페이지 교체
1. Page Replacement

프로세스 동작 중, 필요한 페이지가 물리 메모리에 없는 상황을 의미하며, 페이지 부재가 발생하면 원하는 페이지를 하드디스크의 Swap Space에서 가져오게 된다. 하지만 물리 메모리가 모두 사용중이라 원하는 페이지를 물리 메모리에 적재하지 못한다면 페이지 교체가 일어나게 된다.
2. Thrashing
페이지 부재율(Page fault)이 증가하여 CPU 이용율이 급격하게 떨어지는 현상이다. 다양한 프로세스가 메모리에 올라오면서 메모리의 유효 사용 공간은 줄어들고, CPU의 가동 시간이 올라가면서 자원을 최대한 사용하게 된다.
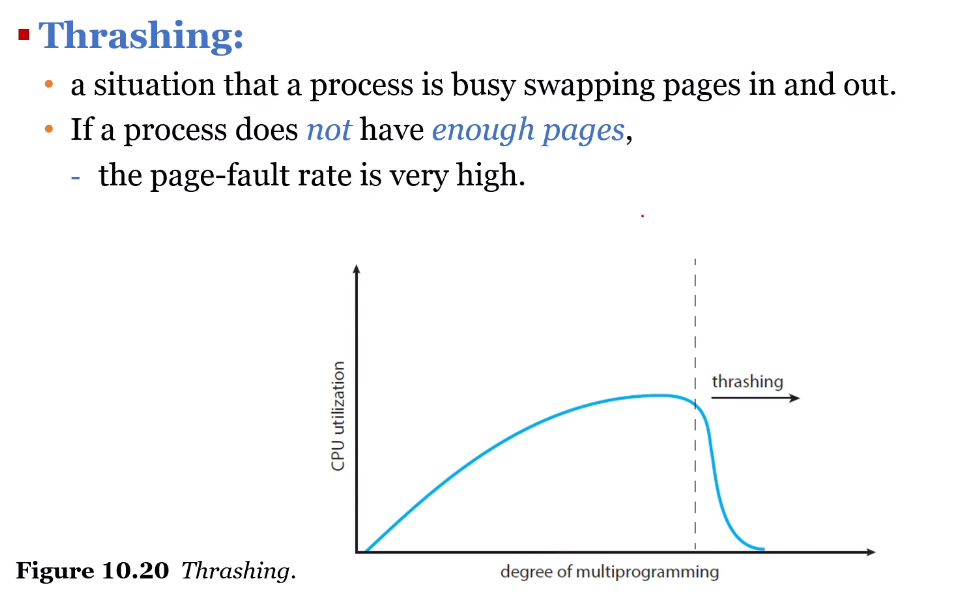
한 번에 여러 개의 프로그램을 실행하게 되면 물리 메모리에서는 프로세스들이 필요로 하는 데이터를 올리기 위한 공간이 충분하지 않다면 열심히 swap in / swap out하게 될 것이다. 이러한 과정이 반복되면서 정상적으로 동작하지 않는 것처럼 보이게 될 수 있는데 이것이 스레싱이다.
'CS > OS' 카테고리의 다른 글
| [OS] 저장장치 관리 (0) | 2023.06.12 |
|---|---|
| [OS] Deadlock (2) | 2023.06.09 |
| [OS] CPU Scheduling (0) | 2023.06.09 |
| [OS] 프로세스 동기화 (0) | 2023.04.13 |
| [OS] 다중 스레드 프로그래밍 (0) | 2023.04.12 |



